



AutoGen is a framework for building multi-agent applications - and we recently released a new v0.4 version - a complete rewrite of the framework.
Some common questions I have gotten include - what can you do with the framework? How do things work underneath? Well .. that’s the focus of this post1!
TLDR;
Installation
AutoGen AgentChat API (with code)
AutoGen Core API (with code)
The broader AutoGen ecosystem (Extensions, Studio, Magentic One)
Conclusion
For low level details, I recommend reviewing the official AutoGen docs and Code on GitHub.
Note: AutoGen is a community driven OSS application built with contributions from multiple organizations, the broader OSS community and researchers/engineers across Microsoft.
All of the code used here is available on the Multiagentbook.com website.
What is an Agent?
For this purpose of this post, we will define an agent as
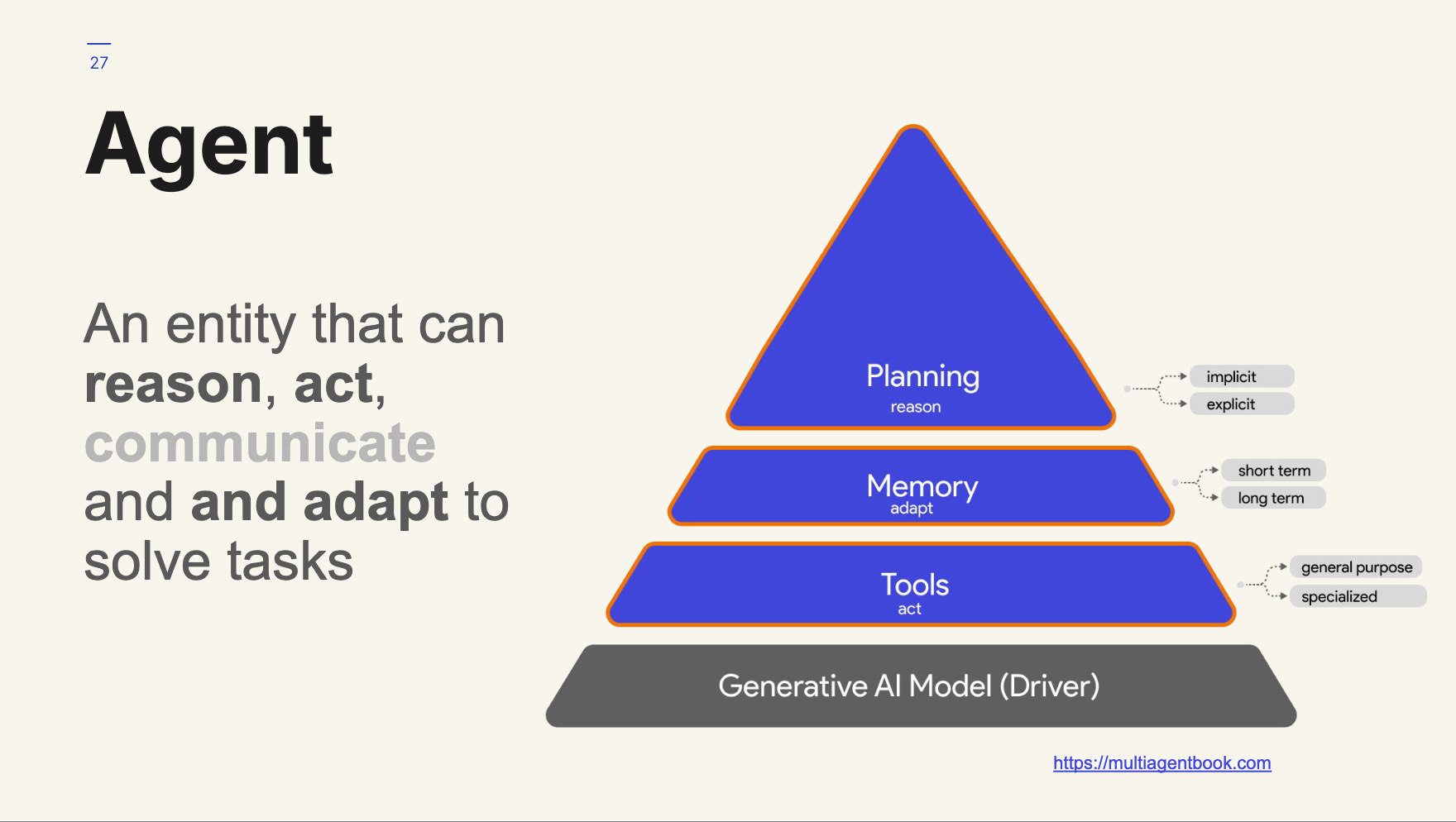
Agent: An entity that can reason, act, communicate and adapt to solve tasks.
Implementation wise, an agent is often some software program where an LLM model drives reasoning and communication, memory enables adaptation and tools enable action.
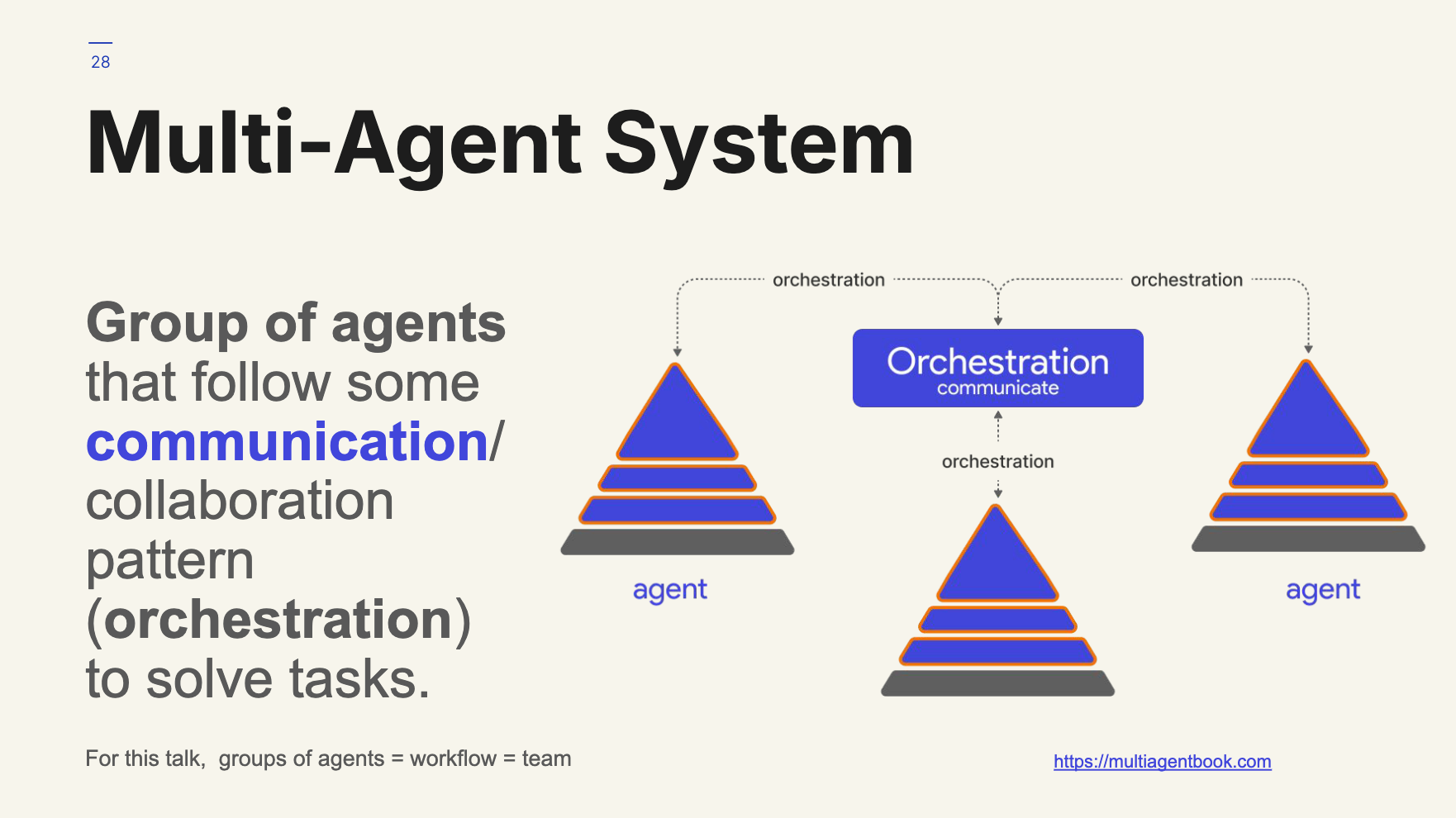
Similarly, we will define a multi-agent system as a:
Group of agents that follow some communication/collaboration pattern (orchestration) to solve tasks.
Installation
If you are new to AutoGen, the general guidance is to first install a python virtual environment (venv or conda). This helps prevent dependency conflict and other issues. Please do it!!
python3 -m venv .venv
source .venv/bin/activate. # activate your virtual env.. or use condaThen install from pip.
pip install -U "autogen-agentchat" "autogen-ext[openai,azure]"Once we have the packages installed, we can write a simple app where an agent is able to respond to math calculation requests by using a simple `calculation function`.
Quickstart with AgentChat
AutoGen offers two APIs -
AutoGen Core: A low level api focused on enabling communication between entities through asynchronous messages. It provides a BaseAgent class abstraction that mostly only cares about implementing a method that runs when this agent receives a message. The developer has to implement every thing else.
AutoGen AgentChat : a high level API called AgentCha built on the Core API and provides useful default presets to accelerate your multiagent application development. For example, the AssistantAgent in AgentChat offers argument abstractions for :
model_client: will use an LLM to respond to received messages
tools: will pipe in these tools to the LLM based on intelligent tool calling capabilities of most modern machine learning models
memory: abstractions to update the model context with external information just in time before an LLM call
Other compelling agent presets include the WebSurferAgent (can address tasks by driving a web browser), UserProxyAgent (can enable delegation to a human as tasks are executed) etc.
AgentChat also provides team abstractions
RoundRobinGroupChat,
SelectorGroupChat,
MagenticOneGroupChat
that enable groups of agents to collaborate on tasks managing this like the order in which agents act, task management (termination conditions) etc.
Let us jump into a quick start example!
import asyncio
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.conditions import MaxMessageTermination, TextMentionTermination
from autogen_agentchat.teams import RoundRobinGroupChat
from autogen_agentchat.ui import Console
from autogen_ext.models.openai import OpenAIChatCompletionClient
def calculator(a: float, b: float, operator: str) -> str:
try:
if operator == '+':
return str(a + b)
elif operator == '-':
return str(a - b)
elif operator == '*':
return str(a * b)
elif operator == '/':
if b == 0:
return 'Error: Division by zero'
return str(a / b)
else:
return 'Error: Invalid operator. Please use +, -, *, or /'
except Exception as e:
return f'Error: {str(e)}'
async def main() -> None:
model_client = OpenAIChatCompletionClient(model="gpt-4o-mini")
termination = MaxMessageTermination(
max_messages=10) | TextMentionTermination("TERMINATE")
assistant = AssistantAgent(
"assistant", model_client=model_client, tools=[calculator])
team = RoundRobinGroupChat([assistant], termination_condition=termination)
await Console(team.run_stream(task="What is the result of 545.34567 * 34555.34"))
asyncio.run(main())The result looks like the following:
---------- user ----------
What is the result of 545.34567 * 34555.34
---------- assistant ----------
[FunctionCall(id='call_GZ0IxcycXwmJfGls9WcWSYPf', arguments='{"a":545.34567,"b":34555.34,"operator":"*"}', name='calculator')]
---------- assistant ----------
[FunctionExecutionResult(content='18844605.0443778', call_id='call_GZ0IxcycXwmJfGls9WcWSYPf')]
---------- assistant ----------
18844605.0443778
---------- assistant ----------
The result of \( 545.34567 \times 34555.34 \) is \( 18,844,605.0443778 \). TERMINATEIn short, we see that following the user’s request, the assistant agent (using the LLM) called the `calculator` tool passing the right arguments extracted from the users natural language query and returns the final correct result.
Fun fact, if you asked GPT4 directly to calculate the above, it returns an answer that appears close, but is wrong (hallucination).
545.34567 multiplied by 34,555.34 equals 18,844,099.8447278.
In the example above, we have only a single agent and we are using a team preset - RoundRobinGroupChat which schedules each agents to act in a round robin fashion. In addition, this setup follows a GroupChat pattern, where a task is solved by agents appending to a conversation history that they both maintain.
Extra Credit!
Naturally, there are a few things you can do to extend this example:
Add more agents (docs). You can define new agents and simply add them to a the list of participants in the GroupChat preset
Explore more team presets (docs). AgentChat offers a
SelectorGroupChat where an LLM (or a specific function you provide) defined the next agent that takes a turn as the task is solved.
Swarm where agents can handoff tasks to other agents based on their capabilities
Termination conditions (docs): In our example, the task ends if any agent responds with the word termination or if a maximum of 10 messages have been exchanged. It also supports termination based on a TimeOut, TokenUsage, External signals etc. See the Termination documentation for more info.

The AutoGen Core API.
The AutoGen Core API provides a foundation for building message-driven multi-agent systems. At its heart are two key capabilities: a way to define agents that can handle specific message types, and an infrastructure to route these messages between agents asynchronously.
Well, what has all of this got to do with creating multiagent systems? How might we accomplish something similar to the AgentChat example above in the Core API? Its a bit verbose. An abbreviated version is shown below (full version here) .
import asyncio
from dataclasses import dataclass
from typing import List, Optional
from autogen_core import (
AgentId,
MessageContext,
RoutedAgent,
SingleThreadedAgentRuntime,
message_handler,
)
from autogen_core.models import ChatCompletionClient
from autogen_core.tool_agent import ToolAgent
from autogen_ext.models.openai import OpenAIChatCompletionClient
@dataclass
class Message:
content: str
# Simple calculator tool
async def calculator(a: float, b: float, operator: str) -> str:
# Implementation details omitted for brevity
pass
class AssistantAgent(RoutedAgent):
def __init__(
self,
model_client: ChatCompletionClient,
tool_schema: List[ToolSchema],
tool_agent_type: str,
max_messages: Optional[int] = None
) -> None:
super().__init__("Assistant with calculator")
# Initialize agent properties
# Implementation details omitted
@message_handler
async def handle_message(self, message: Message, ctx: MessageContext) -> Optional[Message]:
# Message handling logic
# Implementation details omitted ..
pass
async def main() -> None:
# Create runtime
runtime = SingleThreadedAgentRuntime()
# Setup calculator tool
calculator_tool = FunctionTool(calculator, description="Basic calculator")
tools = [calculator_tool]
# Create OpenAI client
model_client = OpenAIChatCompletionClient(model="gpt-4-turbo")
# Register assistant agent with runtime
await AssistantAgent.register(
runtime,
"assistant",
lambda: AssistantAgent(
model_client=model_client,..
max_messages=10
)
)
# Example usage
assistant_id = AgentId("assistant", "default")
response = await runtime.send_message(
Message("What is the result of 545.34567 * 34555.34"),
assistant_id
)
if response:
print(f"Response: {response.content}")
await runtime.stop_when_idle()
if __name__ == "__main__":
asyncio.run(main())Full code here.
Immediately we notice that there is no notion of an interface for tools, memory, model client etc. Let us walkthrough what the code does at a high level:
Runtime
We define a runtime and then register our agents with the runtime.
The runtime manages the life cycle of agents. What does this mean?
As an example, when we run the app above, our AssistantAgent does not really exist. Instead whenever a message is sent to that agent, the runtime checks if an instance exists or then creates one and delivers the message (calling the agent’smessage_handlermethod).Agent Definition:
We define an AssistantAgent based on the RoutedAgent class from AutoGen core. This class has a required `@message_handler` decorator, which tells the runtime two things:What type of messages this agent can handle (through type hints)
How to process those messages when they arrive
The runtime uses this information to route messages to the appropriate handler method of the right agent instance. Note that beyond responding to messages by message type, agents can also subscribe to a specific topic explicitly, and hence receive any message published to that topic! Jazz!
What happens when you hit run?
It begins by the runtime sending a message of “What is the result of 545.34567 * 34555.34”. Because this is of type Message, and the AssistantAgent message_handler has that type, the message gets delivered to it, and the returned response gets printed.
But What Really Happens When You Hit Run?
In reality the runtime does a bit of extra heavy lifting to “deliver a message”
Runtime Instantiation
SingleThreadedAgentRuntime instance is created .. instantiates an empty message queue, a dictionary for agent factories (based on registered agents), empty dictionary for instantiated agents, and a creates a subscription manager.
Runtime.start() .. creates a background task that processes messages from the queue
Agent Creation and Message Delivery
Message flow starts with `await runtime.send_message(..)`. This creates a future for a response, generates a unique message_id (UUID) and creates a SendMessageEnvelope(message, recipient, sender, future, message_id). Puts this envelope in a _message_queue.
At that point, runtime sees no agent exists for AgentId("assistant", "default"), Calls factory function to create AssistantAgent instance and stores that agent instate.
Creates a MessageContext(sender, is_rpc, message_id)
Calls the agents `handle_message()` method and returns a response (it could also publish a message)
Response Handling and Shutdown
Runtime receives the response from the agent
Creates a ResponseMessageEnvelope, and sets the result to the original future
Resolves the awaited runtime.send_message(…)
Shutdown: await runtime.stop_when_idle() .. waits for message queue to empty
The observant developer will recognize all of this as the actor model - a approach to building distributed systems where each entity in responsible for managing its own state (in response to messages it receives) and only impacts others by sending messages.
Importantly, almost any multi-agent system can be represented as a system of distributed entities that exchange messages.
You can compose this simple pattern into complex system behaviors. For example a router pattern (one agent gets the user’s request and routes it to the right agent), a sequential pipeline (each agent outputs a message type that only the next agent is able to receive), agent graphs with parallel execution (messages sent to multiple agents and results gathered) etc.
Distributed and Cross Language Support
While the SingleThreadedRuntime is currently the primary implementation, AutoGen's architecture is designed to support distributed scenarios. The message-passing architecture means agents could potentially run anywhere - different processes, machines, or even organizations - as long as they can connect to the runtime and handle the defined message types.
While the sample above shows a SingleThreadedRuntime, AutoGen Core also supports a (currently experimental) DistributedAgentRuntime where agents may live on separate machines and across organizational boundaries. We only need to register the agent with the runtime and messages can be delivered to them!
Note this design offers a path to cross-language agent development where each agent may be written in any programming language, as long as it can be registered with the runtime and can receive/process delivered messages.
AgentChat uses all of this infrastructure under the hood using the core api and in a lot less lines of code. I built a tool where you can compare implementations across apis/frameworks.
Should I use AgentChat or Core or even AutoGen?
If you are exploring an autonomous multi-agent system where agents “chat” or converse to solve tasks, the abstractions in AgentChat will get you there extremely fast. For example, I was able to replicate the OpenAI Operator Agent in less than 40 lines of code. Rapid prototyping points right there!
However, if you have custom business logic where data needs to flow in a known predefined structure with constraints along the way, you are probably better off expressing this pipeline using the event driven infrastructure in the AutoGen core API


