
Practical Steps to Reduce Hallucination and Improve Performance of Systems Built with Large Language Models
Issue #11 | How can we make systems that integrate LLM's like ChatGPT more reliable? Here are practical techniques (and research) to mitigate hallucination and improve overall performance.


I have spent time building with LLMs over the last 3 years (contributed to GitHub CoPilot), and this post covers some techniques I have used to make systems built with these models more reliable.
TLDR:
This post discusses the following:
Large language models (LLMs) like the GPT series (GPT3, 3.5, ChatGPT) can be powerful tools in building useful applications. If you have used tools like Microsoft Word/Google docs (automatic summarization, grammar correction features), Gmail/Outlook (email autocomplete feature), etc you might have enjoyed some of the time savings enabled by language models within these tools. As a developer or engineering team, there are many exciting opportunities to improve existing workflows or tackle new problems using capabilities provided by LLMs. For example there are new startups exploring areas such as in automatic code review/scanning, question answering on internal documents, automatic data analysis and visualization, research support tools, automated data extraction, smart agents etc., all using LLMs.
Known Challenges with LLMs - Hallucination and Multi-step Reasoning
However, LLMs are probabilistic - i.e., they generate text by learning a probability distribution over words seen during training. For example, given the following words as context “rise and”, an LLM can infer that the next word it should generate that fits this context is likely to be “shine”. While this setup ensures generated text is coherent and human-like (e.g., asking ChatGPT to rewrite the Serenity Prayer in the style of the American Constitution yields some intriguing prose), this resulting text may not be factual, or just plain incorrect (not grounded in the model’s input or training data) - aka hallucination.
In addition, another limitation of LLMs is that they struggle to address tasks that need complex multistep reasoning. For example, asking the model to address mathematical word problems or puzzles often requires that the task is decomposed into steps, some computation applied to solve each step and some transformation applied to aggregate results into a final answer; this remains challenging for LLMs.
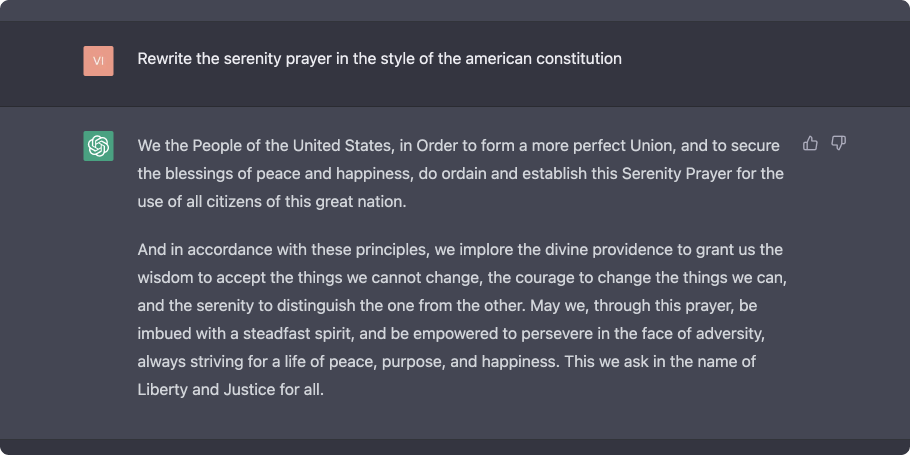
As developers look to build systems with these models, these limitations presents a real challenge as the overall system must meet quality, safety and groundedness requirements. For example, can we trust that an automatic code review provided by an LLM is correct? Or the returned answer to questions on how to handle insurance related tasks is reliable? Or that the generated visualization is faithful to data, or that answers to the research question are factual or grounded in references?
This general area aimed at making LLMs more reliable and safe, has been researched from multiple perspectives. This post begins with an overview of why hallucination will likely always be a problem with LLMs and then discusses steps (and research papers) that help mitigate hallucination and reliability issues.
Why Hallucination is Here to Stay?
Before we get into approaches for reducing hallucination, let us review some thoughts on why LLMs hallucinate.

Large Models as Lossy Compression Modules
From the developer’s point of view, generative models (GPTX, Stable Diffusion etc.) are valuable because they provide a compact, queryable representation of the knowledge represented in the vast amounts of data used to train them. For example:
GPT-2 model (774M parameters) compresses knowledge learned from 40GB of text to a model that fits in about 3GB of model weights (13x factor).
GPT-3 (175B parameters) is trained on 570GB of text*, (which is a filtered version of a larger 45 Terabyte dataset) with 800GB* in model weights. Note: GPT-3 is constantly being updated so this number may be up to date.
BLOOM (176B parameters) was trained on a dataset of 1.5TB, with 329GB of model weights (4.5x factor).
LLAMA (65B parameters) was trained on 4.5TB of text.
Stable diffusion model was trained on about 2 Billion images (LAION2B) (~100 Terabytes of data), with in 2GB of model weights (50k factor!).
Of course, the key to this compression is that a generative model stores a mathematical representation of the relationship (probabilities) between input (text or pixels) as opposed to the input itself. More importantly, this representation lets us extract knowledge (by sampling or running queries/prompts) and also provides some reasoning and extrapolation jiujitsu along the way (e.g., not only does ChatGPT know what the Serenity Prayer is, it can produce a version that is convincingly written in the style of the American Constitution).
I note that compression may not be the best metaphor here, as generative models can produce not just data seen during training but also novel content based on patterns learned from training data.
[Sidebar] The Aleph & Other Metaphors for Image Generation
This Neurips 2022 workshop paper, (which I co-authored) proposes the use of an infinite library metaphor to describe image generation models. The latent space is the library, the dimensions of the latent space are the library hallways, prompts and associated embeddings are the library index, and the generated images are the books. Unlike a regular library index that maps to discrete books, the index of an infinite library is continuous and may map to both books and things between books 😬. Those in-between-things while useful are not necessarily grounded in training data and can present as hallucinations.
Importantly, this type of compression implies a loss of fidelity (see this New Yorker article that discusses this view point using JPEG compression metaphors). In other words, it becomes impossible (or challenging) to reconstruct all of the original knowledge learned. By design. The behavior of hallucination (or the model’s effort to “bullshit” things it cannot recall perfectly) is the price we pay for having this compact, helpful representation of knowledge.
Hallucination - More Feature Than Bug
This understanding that LLMs compress knowledge is helpful in several ways. First, it provides some background in opining on what the future of LLMs might look like - as long as we are interested in a compact generative model helpful for text generation and other tasks, hallucination is an artifact we must learn to accommodate. To really step away from hallucination, we will need very large models that get closer to enabling a 1-1 mapping of model output to text in the training set (… search engine/database territory ) - which pose feasibility (storage and deployment) challenges of their own.
Hallucination is an artifact of compression - more feature than bug.
Further Reading
Xu, Ziwei, Sanjay Jain, and Mohan Kankanhalli. "Hallucination is inevitable: An innate limitation of large language models." arXiv preprint arXiv:2401.11817 (2024).
Practical Steps in Reducing Hallucination and Increasing Performance
The list presented below is not meant to be exhaustive, but useful. It starts out with simple things you can implement with ease, to more involved/experimental ideas. The focus also oscillates between interventions applied to just the LLM (e.g., tweaking model temperature, prompt etc) to the entire system (LLM + UI + other apis via agents). It also avoids techniques that require modifying the model itself (e.g., model fine-tuning, Reinforcement Learning From Human Feedback(RLHF), Low Rank Adaptation(LORA), Constrained decoding etc).
Edit: On Prompt Design
Perhaps the most important lever that a developer has in improving/steering model capabilities lies in prompt design. With the new advances by OpenAI in building models trained to conduct conversational interactions, separating system messages (instructions created by the developer) from user messages (instructions from the end user) this paradigm becomes even more powerful.
The clear opportunity here is to experiment early and frequently with prompting. Also run benchmarks. In many cases, benchmark errors can be fixed by improving your prompt design.There have also been approaches to automatically discover prompts that lead to improved performance (albeit limited increases) for small scale problems.
Yang, Chengrun, et al. "Large language models as optimizers." arXiv preprint arXiv:2309.03409 (2023).
1. Temperature (Turn it down …)
When building with LLMs (be it a HuggingFace model like FLAN-T5 or the OpenAI GPT-3 api), there are several parameters available, including a temperature parameter. A model's temperature refers to a scalar value that is used to adjust the probability distribution predicted by the model. In the case of LLMs, the temperature parameter determines the balance between sticking to what the model has learned from the training data and generating more diverse or creative responses. In general, creative responses are more likely to contain hallucinations.

In the example above, the result of the query (what was the HMS Argus) is fairly accurate when temperature=0. At temperature =1, the model takes creative liberties and discusses the dates of the vessel being decommissioned and sold for scrap - those dates are incorrect. In addition, temperature=0 always yields the same deterministic most likely response (valuable for building/testing stable systems)
💡Opportunity: For tasks that require veracity (e.g., visualization generation), strive towards an information dense context and set temperature=0 to get answers grounded in context.
2. Use An External Knowledge Base.
As discussed earlier, hallucination is an artifact of the compression property of LLMs i.e., it occurs when the model tries to recreate information it has not explicitly memorized or seen. By providing access to relevant data (adding to the prompt) from a knowledge base at prediction, we can convert the purely generation problem to a simpler search or summarization problem grounded in the provided data. This approach is not novel. Tools like Perplexity.ai and You.com first fire off search queries and use LLMs to synthesize/summarize results ideally grounded in those search results (with references to source pages for verification).
In practice, retrieving relevant data (passages) from a knowledge base is non-trivial. Existing research in Open Domain Question Answering and Retrieval Augmented Generation (RAG) remain quite relevant here. For example the Dense Passage Retrieval paper proposes training a question encoder and a passage encoder that embed both question and passage into the same embedding space. At query time, the question encoder is used to retrieve passages likely to answer the question. Also the Hypothetical Document Embedding (HYDE) paper proposes using the initial answer from an LLM as a soft query in retrieving relevant passages.
Karpukhin, Vladimir, et al. "Dense passage retrieval for open-domain question answering." arXiv preprint arXiv:2004.04906 (2020).
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
Gao, Luyu, et al. HYDE "Precise Zero-Shot Dense Retrieval without Relevance Labels." arXiv preprint arXiv:2212.10496 (2022).
Ma, Kaixin, et al. "Open-domain Question Answering via Chain of Reasoning over Heterogeneous Knowledge." arXiv preprint arXiv:2210.12338 (2022).
In the temperature example in step #1, we can use the HYDE approach - i.e., we take the generated output (with its inaccuracies), retrieve relevant grounded passages from an external database like Wikipedia, use these passages as part of the prompt and get correct results.
The has also been more recent work that take things a bit further and explore ways to use the weights from a generative model itself as indices or parts of indices in retrieval. Retrieval-augmented generation (RAG) — models which combine pre-trained parametric and non-parametric memory for language generation.
Lewis, Patrick, et al. "Retrieval-augmented generation for knowledge-intensive nlp tasks." Advances in Neural Information Processing Systems 33 (2020): 9459-9474.
Hu, Ziniu, et al. "REVEAL: Retrieval-Augmented Visual-Language Pre-Training with Multi-Source Multimodal Knowledge Memory." arXiv preprint arXiv:2212.05221 (2022).
⚠️ Caution: More work is still needed to filter/rank retrieved passages (there may be billions of passages) and make decisions on how much of the LLM context budget is used in this exercise. Also, retrieval and ranking can add latency, an important concern for real-time user experiences.
3. Chain of Thought Prompting (and Other Prompting Strategies)
A well known flaw of LLMs is their poor performance on tasks that require multi-step reasoning e.g., arithmetic, or logic tasks. An LLM may write reams and reams of convincing Shakespeare but fail to correctly multiply 371 * 246. Recent work shows that when the model is offered some examples (few shot) in decomposing the task into steps (a chain of thought) and aggregating its result, performance significantly improves. Even better, it turns out that simply adding “Let’s think step by step“ to prompts without any hand crafted examples elicits similar improvements 🤯🤯. Zero shot chain of thought.
Kojima, Takeshi, et al. "Large language models are zero-shot reasoners." arXiv preprint arXiv:2205.11916 (2022).
Experimental results demonstrate that our Zero-shot-CoT, using the same single prompt template, significantly outperforms zero-shot LLM performances on diverse benchmark reasoning tasks including arithmetics (MultiArith, GSM8K, AQUA-RAT, SVAMP), symbolic reasoning (Last Letter, Coin Flip), and other logical reasoning tasks (Date Understanding, Tracking Shuffled Objects), without any hand-crafted few-shot examples, e.g. increasing the accuracy on MultiArith from 17.7% to 78.7% and GSM8K from 10.4% to 40.7% with large InstructGPT model (text-davinci-002), as well as similar magnitudes of improvements with another off-the-shelf large model, 540B parameter PaLM
More references on prompting strategies.
Chain of Thought: Wei, Jason, et al. "Chain of thought prompting elicits reasoning in large language models." arXiv preprint arXiv:2201.11903 (2022).
Chain of Thought Evaluation: Suzgun, Mirac, et al. "Challenging BIG-Bench tasks and whether chain-of-thought can solve them." arXiv preprint arXiv:2210.09261 (2022).
Shi, Freda, et al. "Language models are multilingual chain-of-thought reasoners." arXiv preprint arXiv:2210.03057 (2022).React Prompting: Yao, Shunyu, et al. "React: Synergizing reasoning and acting in language models." arXiv preprint arXiv:2210.03629 (2022). Explores the use of LLMs to generate both reasoning traces and task-specific actions in an interleaved manner, allowing for greater synergy between the two: reasoning traces help the model induce, track, and update action plan.
Tree of Thought : Yao, Shunyu, et al. "Tree of Thoughts: Deliberate Problem Solving with Large Language Models, May 2023." arXiv preprint arXiv:2305.10601 (2023). Proposes the generation of multiple plans with multiple steps and then voting for the best plan.
Contrastive Chain of Thoughts: Chia, Yew Ken, et al. "Contrastive Chain-of-Thought Prompting." arXiv preprint arXiv:2311.09277 (2023). | Not very novel .. advocates for adding both valid and invalid reasoning demonstrations, to guide the model to reason step-by-step while reducing reasoning mistakes.
System 2 Attention: Weston, Jason, and Sainbayar Sukhbaatar. "System 2 Attention (is something you might need too)." arXiv preprint arXiv:2311.11829 (2023). Not particularly novel, employs a two stage process where the the LLM is first asked to sanitize the prompt (remove distracting information) before generating results.
Thread of Thought: Zhou, Yucheng, et al. "Thread of Thought Unraveling Chaotic Contexts." arXiv preprint arXiv:2311.08734 (2023). | Nothing particularly novel, proposes adding “Walk me through this context in manageable parts step by step, summarizing and analyzing as we go” to prompts to improve performance.
Emotion Prompt: Li, Cheng, et al. "Emotionprompt: Leveraging psychology for large language models enhancement via emotional stimulus." arXiv preprint arXiv:2307.11760 (2023). | Questionable novelty here .. proposes adding emotional words like “this is very important to my career“ to prompts in order to improve performance.
💡Opportunity: Always experiment with adding “Let’s think step by step“ to your prompts!!!
⚠️ Caution: Few shot Chain of thought does require some experimentation and effort to craft examples. In addition, many of these techniques require multiple LLM inference calls, which might prove to be cost prohibitive (latency and compute).
4. Self Consistency
This general approach follows a “wisdom of the crowd” or “majority vote” or “ensembles” approach to improve the performance of models. Consider that you could prompt the model to explore diverse paths in generating answers; we can assume that the answer most selected across these diverse paths is likely to be the correct one. How the diverse answers are generated and how they are aggregated (to infer the correct answer) may vary.
The Self-Consistency (Wang et al) paper introduce a new self-consistency decoding strategy that samples diverse reasoning paths. First, a language model is prompted with a set of manually written chain-of-thought exemplars. Next they sample a set of candidate outputs from the language model’s decoder, generating a diverse set of candidate reasoning paths. Finally, answers are aggregated by marginalizing out the sampled reasoning paths and choosing the answer that is the most consistent among the generated answers.
Wang, Xuezhi, et al. "Self-consistency improves chain of thought reasoning in language models." arXiv preprint arXiv:2203.11171 (2022).
Arora, Simran, et al. "Ask Me Anything: A simple strategy for prompting language models." arXiv preprint arXiv:2210.02441 (2022).
⚠️ Caution: Multiple calls the model is expensive and can introduce latency issues.
5. Model Correctness Probabilities, Self Evaluation
This one is simple. It turns out that if you ask a model to generate answers and ask it to generate the probabilities that its answers are correct, these probabilities are mostly well calibrated 🤯🤯. That is, the model mostly knows what it does and doesn’t know. 🤯🤯
The insight here is that for each generated answer to a prompt, we can get these probabilities and use that in filtering results (discard results that are likely incorrect).
Kadavath, Saurav, et al. "Language models (mostly) know what they know." arXiv preprint arXiv:2207.05221 (2022).
Lin, Stephanie, Jacob Hilton, and Owain Evans. "Teaching models to express their uncertainty in words." arXiv preprint arXiv:2205.14334 (2022).
Tian, Katherine, et al. "Just ask for calibration: Strategies for eliciting calibrated confidence scores from language models fine-tuned with human feedback." arXiv preprint arXiv:2305.14975 (2023). EMNLP 2023
Furthermore, models can be chained as evaluators of their own output where we make recursive calls to the model to refine and improve its own output until we get a good result. Madaan et al find a 20% improvement in metrics using this approach. Noah et all introduce the concept of self reflection and reasoning traces (dynamic memory) as an approach to improving task performance
Self-Refine: Iterative Refinement with Self-Feedback Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Sean Welleck, Bodhisattwa Prasad Majumder, Shashank Gupta, Amir Yazdanbakhsh, Peter Clark
Shinn, Noah, Beck Labash, and Ashwin Gopinath. "Reflexion: an autonomous agent with dynamic memory and self-reflection." arXiv preprint arXiv:2303.11366 (2023). An approach that endows an agent with dynamic memory and self-reflection capabilities to enhance its existing reasoning trace and task-specific action choice abilities.
💡Opportunity: A low hanging fruit is that we can leverage this capability of LLMs in making the model decline to answer when it is not confident instead of hallucinating. E.g., experiment with adding phrases like “Answer the question as truthfully as possible and if you are unsure, respond with ‘Sorry, I do not know the answer to that question’ ”. You can use this as signal to either invite the user to provide additional context or automatically retrieve context from an external knowledge base (#2 above).
⚠️ Caution: This approach requires reframing your task such that the model can predict the probability of correctness, and requires multiple forward passes through the model to predict correctness probabilities for each candidate result (additional costs 💰💰, latency).
6. Task Decomposition and Agents
Related to #2 (chain of thought) above, this approach explores creating an initial router agent that seeks to explicitly decompose the user’s prompt into specific sub tasks. Each subtask is then handled by a specific expert agent. Note that an agent here is also an LLM (i.e., a forward pass through an LLM with optional abilities to act in the real world via api’s e.g., creating a calendar invite, payments, etc). Also note that each agent may have to rewrite/reformulate the prompt it receives in order to apply its capabilities. The demonstration by Fixie.ai shows an example of chaining multiple agents to solve tasks. There has also been research aimed at teaching LLMs to directly interact with APIs (e.g., the ACT-1 model from Adept.ai and work like ToolFormer).
Consider the following examples of agents:
User: “Who is the current Speaker of the House of Representatives in the United States?”. The router agent detects that this is a search related task and hands it off to a search agent. Search agent runs a wikipedia + bing/google search and a summarization agent answers based on retrieved data.
User: “Am I free to meet with Andrej Karpathy in person next week in San Francisco?”. The router agent decomposes this into tasks handled by a scheduling agent and a weather agent. The scheduling agent may further decompose this this into several queries it can answer e.g., what are calendar availabilities for next week (a calendar agent), while the weather agent fetches weather conditions in San Francisco. Finally a summarization agent synthesizes the final answer.
User: “Write a 20 page novel (3 chapters) about a superhero who started out as a cabbage patch farmer but quickly grew into the Defender of Metropolis City, aided by his 5 sidekick super heroes”. The router decomposes this into tasks handled by two agents - a plot agent and a writing agent. A plot agent may take a first pass writing a high level plot and describing the key characters and their interactions across each chapter (maintaining inter-chapter consistency). A writing agent may then take each chapter structure and some relevant metadata and expand each chapter.
Zhou, Denny, et al. "Least-to-most prompting enables complex reasoning in large language models." arXiv preprint arXiv:2205.10625 (2022). Proposes decomposing prompts into subtasks and solving.
Creswell, Antonia, and Murray Shanahan. "Faithful reasoning using large language models." arXiv preprint arXiv:2208.14271 (2022). Propose a method that causes LLMs to perform faithful multistep reasoning via a process whose causal structure mirrors the underlying logical structure multi-step problems.
⚠️ Caution: In theory, the promise of composable agents is attractive. In practice, it often requires a deep apriori understanding of the problem domain and careful customizations for good results. For example, an effective scheduling agent must be programmed with examples on how to use the google calendar api, aggregate and represent results. While several of the papers referenced above hint at a “one agent to rule them all” scenario, it is unclear that that reality is available today.
Finally, there is also the cost and latency impact of multiple passes through an LLM.
7. Benchmark Your Model/System
One interesting side effect of the rise of LLMs is the seeming decline in focus on building evaluation benchmarks? This may be due to a few factors:
Benchmarks get obsolete fast.
The LLM field is literally experiencing a Cambrian explosion in terms of progress. Meticulously crafted benchmark datasets are all but solved with each new LLM iteration making them less valuable?Too many tasks to track
LLMs are foundation models that can solve multiple tasks. Keeping track of these tasks can be come tedious. Can we just assume it “works”?Prompt engineering is more art than science
LLM performance can be fickle. For example an engineering hack (e.g., chain of thought prompting) can lead to huge changes in benchmark performance with the underlying model untouched 🤯🤯. This makes benchmark results less reliable?We do not fully understand LLMs
The LLM field is still nascent .. we discover new things about LLM behaviors quite frequently. What looks like poor task performance today may be due our poor understanding of how LLMs work?
Either way, you do need principled methods (metrics, evaluation dimensions specific to your use case) to determine if any or all of the measures suggested so far results in behaviors you care about (e.g., improvements in accuracy, calibration, robustness, fairness, bias, toxicity, and efficiency).
Liang, Percy, et al. "Holistic evaluation of language models." arXiv preprint arXiv:2211.09110 (2022). Holistic Evaluation of Language Models
Bang, Yejin, et al. "A Multitask, Multilingual, Multimodal Evaluation of ChatGPT on Reasoning, Hallucination, and Interactivity." arXiv preprint arXiv:2302.04023 (2023).
💡Opportunity: Invest time in creating a benchmark to calibrate your overall system performance for a set of tasks associated with your use case. Creating those benchmarks is beyond the scope of this article. Note, that many of the issues you discover can be fixed by improving your prompts or exploring model-self repair strategies.

In one of my recent projects, applying LLMs to the task of automated visualization, designing metrics for evaluating system reliability (visualization error rate) and semantic quality (self-evaluated visualization quality) of output proved to be valuable.
8. Build Defensive APIs and UIs
The idea of a defensive API or user interface (UI) is one that mostly acknowledges bad things can happen (e.g., hallucination amongst other things) when we build with machine learning models and designs to mitigate them. Remember that your UI is the primary representation of your entire system (backend, servers, micro services, calls to a model api … everything) and that trust can be established or lost based on the experience offered to the user.

Amershi, Saleema, et al. "Guidelines for human-AI interaction." Proceedings of the 2019 chi conference on human factors in computing systems. 2019. Many of the defensive UI actions below are covered in this paper.
Some actions you can take to build defensive UIs for systems that integrate LLMs:
State Capabilities and Limitations
A first low hanging fruit is to sufficiently prime your users to exercise vigilance, and help them understand what the system can or cannot do. For example, you might tell them the system can help them with generating multiple ideas which may contain factual errors or biases. Bonus - create a UI that supports capability discovery.Provide Control Affordances
Another approach is to provide affordances for the user to edit, update, verify or even disable the model output. While directly showing the end result can prevent distractions (and is a good thing), it should not be the only affordance. Controls can also be avenues to encourage user vigilance.Provide Explanations
As users interact with a system to accomplish their goals, a good UI should also play the role of teacher, guiding the user on how best to accomplish their goals. For example, a UI that illustrates the thought process or behavior of the system (e.g., how tasks are decomposed, results from intermediate steps) teaches the user to make sense of final output, design their own error recovery strategy (e.g., the best way to rephrase the prompt etc.) and avoid model pitfalls. For example, in the Fixie.ai prototype, the UI visualizes the intermediate steps performed by multiple agents which are chained together in answering user requests.Manual Correctness Checks with Graceful Degradation
Implement manual checks for correctness (mostly based on your domain understanding of the use case), checks for model failure and update the user or offer alternatives accordingly. For example, the model may occasionally fail to return structured responses (e.g., JSON), add parse checks and recovery code (e.g., call model to fix error, or retry query ) or pass a well formed error message to the user. This often requires heavy manual testing and multiple prompt designs that mitigate identified errors.Explore tools like Guardrails for validating the output of yoru LLM pipelines. Explore tools like Guidance for controlled generation.
Model and Leverage User State
Keep track of user interaction history and intelligently reuse them as an additional knowledge source (step #2 above). Now, as to how to implement this? 🤷 .. it depends on your use case and I’d say, experiment. Note that adding irrelevant history can throw off the model while not using history at all can miss out on important context.Avoid Lazy-LLMing, Bake in Domain Expertise
LAZY-LLMing - when developers make their solutions less reliable by unnecessarily adding failure points via LLMs!
In general, do not use LLMs for any parts of the problem solution that can be reliably solved without LLMs. Instead, delegate known sub-problems to tools or systems that already reliably solve that problem. This way you avoid additional LLM failure points in your application.
Example:
Task: Write a poem about a given zip code's location 📝
❌ Bad: LLM - "Write a poem about zip code 12345" (uses the LLM like a dictionary to infer the location, inducing high hallucination risk!)
✅ Good: Use a geocoding API to get <city name>, then ask LLM to "Write a poem about <city name>" 🌆
Conclusion
LLMs have limitations e.g., they have limited logic/reasoning capabilities and will hallucinate. Several of the steps suggested in these articles are helpful in mitigating these limitations. It goes without saying that caution is required when addressing use cases that require factual results or require complex multistep reasoning.
LLMs are also expensive - approaches that require multiple LLM api calls might prove to be too expensive in practice.

Are there techniques you are experimenting with not mentioned above or things missed in this article? Share in the comments below!
Further Reading
Techniques to improve reliability: Notebook from the OpenAI team that covers similar topics and papers.
ChatGPT is a blurry jpeg of the web: New Yorker article by Ted Chiang that offers analogies from jpeg compression in explaining reasons for hallucination.
Thoppilan, Romal, et al. "Lamda: Language models for dialog applications." arXiv preprint arXiv:2201.08239 (2022).
Ge, Tao, et al. "Extensible Prompts for Language Models." arXiv preprint arXiv:2212.00616 (2022). Instructs an LLM with not only NL but also an extensible vocabulary of imaginary words that are introduced to help represent what NL words hardly describe, allowing a prompt to be more descriptive
Xu, Ziwei, Sanjay Jain, and Mohan Kankanhalli. "Hallucination is inevitable: An innate limitation of large language models." arXiv preprint arXiv:2401.11817 (2024).
About the Author
If you found this useful, cite as
Dibia, V. (2023). Generative AI: Practical Steps to Reduce Hallucination and Improve Performance of Systems Built with Large Language Models. In Designing with ML: How to Build Usable Machine Learning Applications. Self-published on designingwithml.com.
Victor Dibia is a Research Scientist with interests at the intersection of Applied Machine Learning and Human Computer Interaction. His recent work explores building tools that integrate LLMs for code and image generation models.
Ideas in this article my own.
Really enjoyed reading this. Currently doing research on hallucinations and I'm glad I came across this.
Great. work. Very in-depth coverage.