
How to Generate Visualizations with Large Language Models (ChatGPT, GPT4)
Issue #12 | How to build tools for automatic data exploration, grammar-agnostic visualizations and infographics using Large Language Models like ChatGPT and GPT4.

This post provides a high-level description of the design of an open source tool (LIDA) that supports users in automated data exploration and visualization/infographic generation using LLMs and image generation models (IGM’s).
TLDR; LIDA provides the following capabilities.
Data Summarization: Create a compact but information dense natural language representation of datasets, useful as grounding context for data operations with LLMs.
Automatic Data Exploration: Given some raw data, come up with data exploration goals that make sense for this data. EDA for free!
Grammar Agnostic Visualization Generation: Generate visualizations in any language, any visualization grammar (e.g., matplotlib, ggplot, altair etc).
Infographic Generation: Generate stylized but “data-faithful” infographics, directly from data. Extensive applications in interactive data storytelling.
Visualization Ops: Enables a set of operations on generated visualizations including - natural language based visualization refinement (.e.g change the x axis to .. translate chart to … zoom in by 50% etc), visualization explanation (code explanation, accessibility descriptions), visualization code self-evaluation (evaluation on dimensions such as aesthetics, compliance, type, transformation etc). Many applications here for accessibility, education and learning.
Code for lida is open source (MIT) and available here. Gallery of example visualizations here.
Dibia, Victor. "LIDA: A Tool for Automatic Generation of Grammar-Agnostic Visualizations and Infographics using Large Language Models." Proceedings of the 61th Annual Meeting of the Association for Computational Linguistics: System Demonstrations arXiv preprint arXiv:2303.02927 (2023).

Background and Motivation
In 2018 (eons ago .. in ML timelines), Cagatay Demiralp and I were both Scientists at IBM Research NY, and were curious about building ML tools that generate visualizations from data. Such tools are valuable for users who lack the expertise to ask the right questions, select the right visual encoding or create charts (either via code or GUI tools). Could we really give raw data to a trained ML model, and get a set of initial relevant visualizations, with zero user input? Ideally, if we were successful, it would mean a system that could learn about visualization best practices directly from vast amounts of example data, addressing limitations of existing systems that relied on heuristics for visualization generation. And we succeeded! In 2018, we designed Data2Vis, the first system that provided a learning-based method for end-to-end automatic visualization generation from data. Our key insight back then was to represent data as text (preprocessed samples from a json file), visualizations as text (Vega-Lite JSON specification), and cast the problem as a sequence translation task (using sequence to sequence models), similar to language translation. However, Data2Vis had several limitations including - complex data/training requirements (custom paired data), language/grammar specific pipelines (it only worked with VegaLite!), non-existent user control (users could not express their intent), focus on only visualization generation, amongst other things.
Today, with advances in Large Language Models like ChatGPT/GPT-4 that have immense language modeling and code writing capabilities, there exists clear paths to addressing these limitations and creating systems that can address a wide swath of visualization-related tasks - automated data exploration, visualization generation, visualization explanation, visualization QA, data story generation etc.
We can give novices (users who are not skilled in visualization creation) new capabilities in data visualization. For skilled users, we can significantly shorten visualization authoring time.
These are the underlying motivations for LIDA.
Approach - Visualization as a Multi-Stage Generation Problem
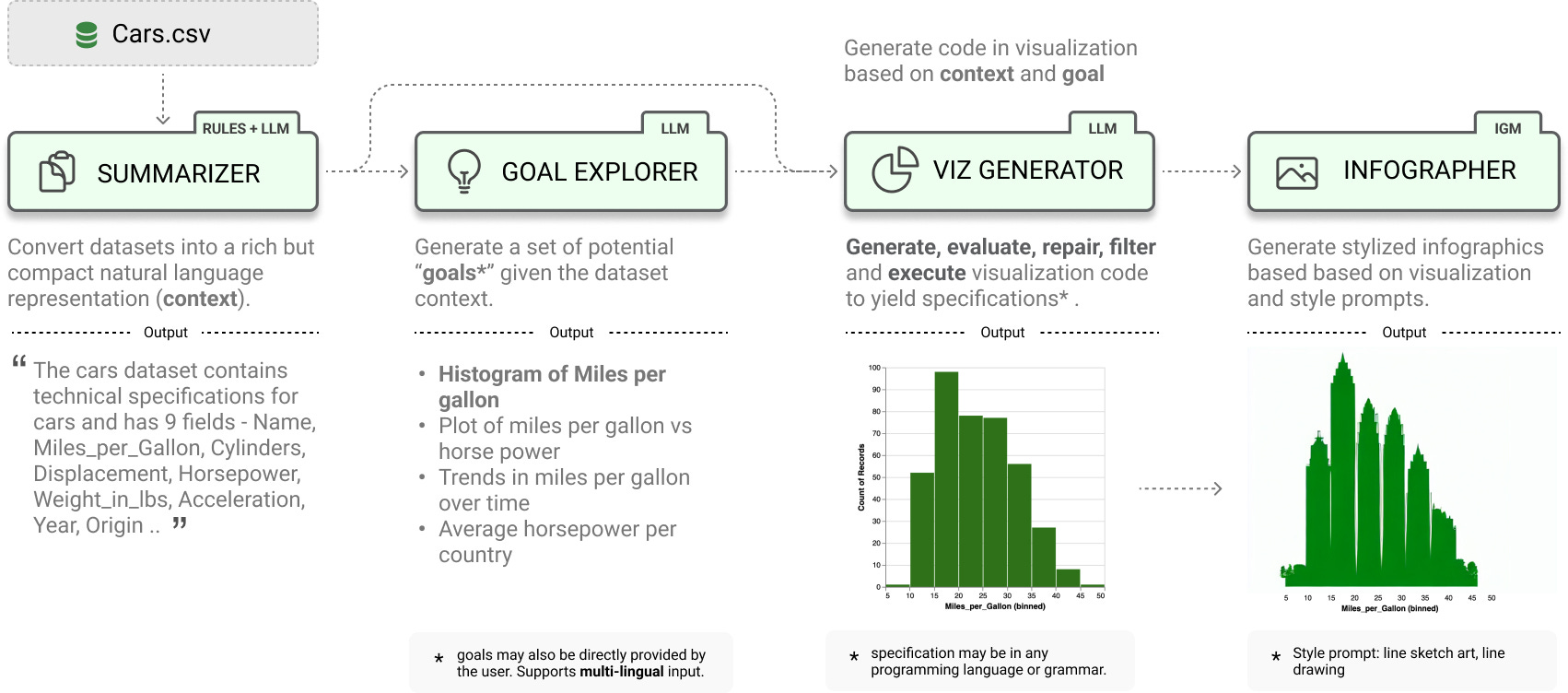
Systems that support users in the automatic creation of visualizations must address several subtasks - understand the semantics of data, enumerate relevant visualization goals and generate visualization specifications.
In this work, we pose visualization/infographic generation as a multi-stage generation problem and argue that well-orchestrated pipelines based on large language models (LLMs) and image generation models (IGMs) are suitable to addressing these tasks. We present LIDA, a novel tool for generating grammar-agnostic visualizations and infographics. LIDA comprises of 4 modules - A SUMMARIZER that converts data into a rich but compact natural language summary, a GOAL EXPLORER that enumerates visualization goals given the data, a VISGENERATOR that generates, refines, evaluates, repairs, executes and filters visualization code, and an INFOGRAPHER module that yields data-faithful stylized graphics using IGMs.
The following section describes these modules. See the paper for additional details. Example excerpts of the prompts used are also shown.
Data Summarization
A system that generates visualizations from data should have some “familiarity” with the data. However, we cannot offer the entirety of the data to the model (context limitations). Rather, we need a compact but information dense representation of the data that the model can use as “grounding context” in addressing visualization tasks.
One of the common mistakes made by developers seeking to get ChatGPT to “analyze” data is to attempt to send the entire dataset to the model, or randomly sample dataset rows. A more careful approach is more beneficial.
The SUMMARIZER module in LIDA achieves this in two stages. First, we construct a dictionary with properties (i) Extracted atomic types (e.g., integer, string, boolean) based on the pandas library (ii) General data field properties (e.g., # of unique samples, max and min, range etc.) and an illustrative non-null list of n samples from each column. This summary is then optionally enriched by an LLM or a user via the LIDA ui to include - semantic description of the dataset, field descriptions and predicting semantic type for each field.
[Prompt Excerpt: You are a skilled visualization expert that can annotate a given data representation carefully. Always add a description of the dataset and descriptions for each field ...]

Goal Exploration (Automatic EDA)
This module generates data exploration goals, given the data summary. In our implementation, we express this as a multitask generation problem for an LLM to solve. For each goal, the LLM must generate a question (hypothesis), a visualization that addresses the question and rationale. Requiring the model to produce rationale tends to lead to more meaningful goals.
[Prompt Excerpt: You are a skilled data analyst. Given the data summary provided, generate a set of n goals that fit the data. …]

Visualization Generation
This module generates code that addresses the provided goal, given the data summary and based on a provided code scaffold. A scaffold here consists of a template, which the model “fills-in” as well as post processing steps for quality (e.g., removing extraneous generated text that may lead to compile errors). The VISGENETOR module implements generic scaffolds for all supported grammars. Note that a scaffold is not necessary for the LIDA approach to work, but is trivial to implement and improves reliability.
[Prompt Excerpt: You are an assistant highly skilled in writing code for visualizations .. Write code that meets the stated visualization goal, using the provided code scaffold. Address the task by filling in sections of the code scaffold .. ]

This module also implements submodules for executing generated code, filtering errors, self evaluation (the model is tasked with evaluating generated code .. more below) and auto repair (model is tasked with repairing visualization code based on some feedback that may come from the model itself, from the user or from compiler error).
Infographics Generation
This module is tasked with generating stylized graphics based on output from the VIZGENERATOR module. It implements a library of visual styles described in natural language that are applied directly to visualization images. Note that the style library is editable by the user. These styles are applied in generating infographics using the text-conditioned image-to-image generation capabilities of diffusion models [5] implemented using the Peacasso library api. An optional post processing step is then applied to improve the resulting image (e.g., replace axis with correct values from visualization, removing grid lines, and sharpening edges).

VizOps - Operations on Generated Visualizations
Given that LIDA represents visualizations as code, we can perform a list of interesting operations on this representation.
Natural language based visualization refinement. LIDA offers an interactive natural language UI where the user can issue commands like change the x axis to .. translate chart to … zoom in by 50% etc). These commands can be chained as conversations that build up.
Visualization explanations and accessibility. We can task the model to explain the code and generate accessibility descriptions for the visualizations. There are applications here (code explanation, accessibility descriptions),
Visualization code self-evaluation and repair : We can task the model with evaluating generated code on multiple dimensions - e.g., code accuracy, transformations, compliance, visualization type, encoding and aesthetics
Visualization recommendation: Given some context (goals, or an existing visualization), LIDA can recommend additional visualizations that may be useful to the user (e.g., for comparison, or to provide additional perspectives or directions).
System Evaluation
Designing evaluation benchmarks or metrics for systems that integrate LLMs often is tricky. First, the metric must be meaningful to the specific task (i.e., we should be able to learn about task performance from this metric and take action to improve). Second, we must be critical in interpreting performance results as LLMs like ChatGPT/GPT-4 may have seen the task in some form within its vast training set. For example, if LIDA proposes interesting data exploration goals, is this because it extracted patterns based on the data summary or it regurgitated goals in its training set.
Given the above caveats, in this work we propose two high level approaches to benchmarking the performance of LIDA. First, we compute overall visualization error rates to provide signals on the reliability of the LIDA pipeline as a tool for automated visualization generation. Next, we compute self-evaluated visualization quality scores to provide information on the quality of generation visualizations.
Visualization Error Rate
Visualization error rate is computed as the percentage of visualizations that result in compilation errors. In the current benchmark, LIDA is tasked with generating 5 goals from datasets (sourced from the vega datasets repo) and generating visualizations (one-shot) for each goal across multiple grammars.
In theory, the error rates can be driven to zero, by recursively applying the self-evaluation and repair modules.
This metric has been valuable in improving the prompt scaffold. For example qualitative inspection of error cases provide signals on how changes to prompts affect system reliability e.g., how multiple approaches to handling date transforms might lead to error conditions.
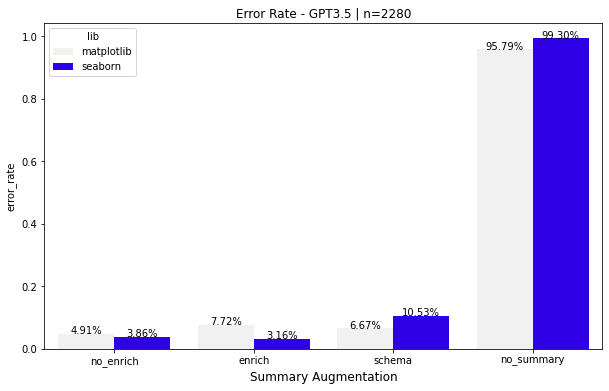
The chart above shows error rates from 2280 charts created by LIDA using datasets from the vega datasets repository. It shows 4 conditions i) no_summary : only the dataset filename is provided to the model. Worst performance ii) schema: only the list of field names and file name are provided to the model iii) no_enrich: a data summary is provided to the model but without enrichment such as data description, field descriptions or semantic types iv) enrich: a summary is provided with LLM-based enrichment.
We see that providing a data summary is beneficial and that charts with Seaborn have the lowest error rates (likely due to the expressivity of the Seaborn grammar).
Self Evaluated Visualization Quality Metric
Existing research shows that recent LLMs such as GPT4 encode world knowledge and are fairly well calibrated (can assess the correctness of their output) [3]. For example, with no additional fine tuning, they provide human-level performance on various professional and academic benchmarks (including law, medicine, art, history, biology etc), including passing a simulated bar exam with a score around the top 10% of test takers [4].
Our observations working with GPT3.5/GPT-4 for visualization suggest similar results. More importantly, GPT-4 has learned to encode visualization best practices and can apply these in generating critiques of visualization code across multiple dimensions.
For this self-evaluated visualization quality metric, we use GPT-4 to score visualization code across 6 dimensions - code accuracy, transformations, compliance, visualization type, encoding and aesthetics.
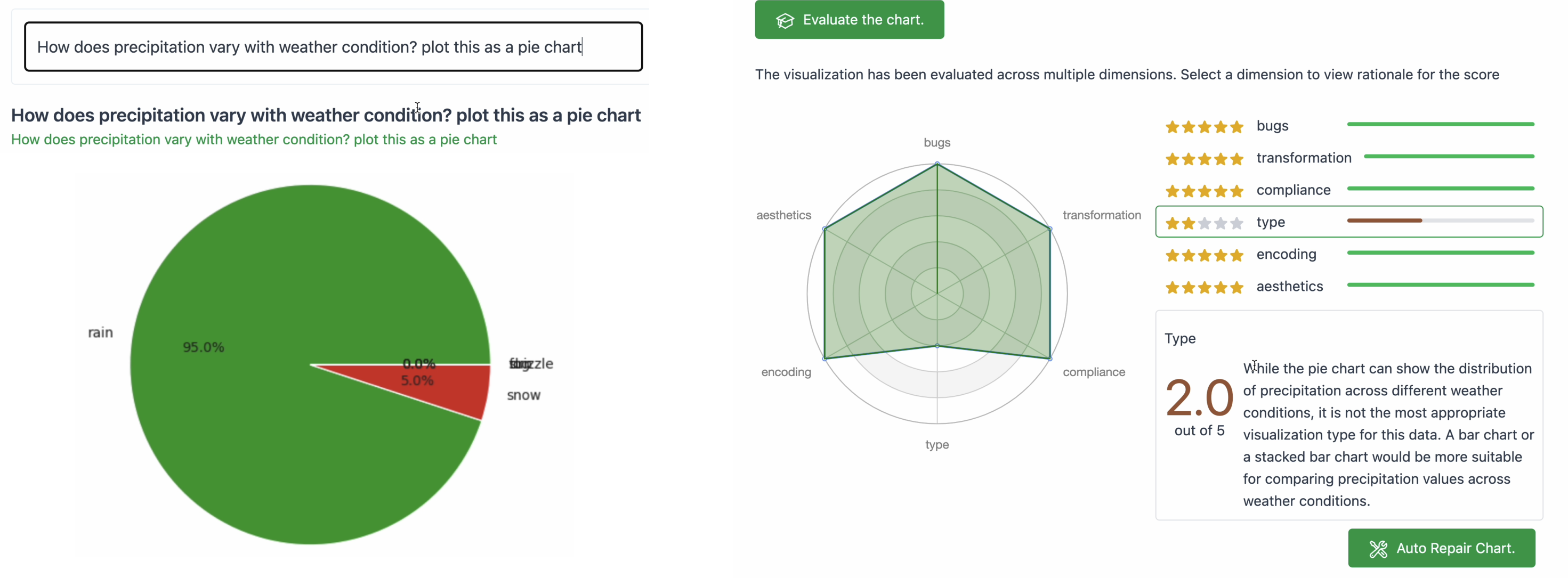
Qualitative Evaluation
The reader is encouraged to view the gallery here for more qualitative examples of visualizations created by LIDA. Overall, GPT 3.5/4 does shows excellent results across multiple stages of the visualization task - inferring the appropriate transformations to apply to data (e.g., pivot tables, creating new columns, new datasets, sometimes loading external data like maps etc), importing relevant libraries (e.g., geopandas for lat/long data), self evaluation of chart quality, chart accessiblity descriptions, chart explanation amongst other capabilities.

Caveat: Many of the datasets in the gallery above have been seen by GPT4 and there is a chance that the task is simply given this exposure (a known evaluation limitation with LLMs). However, experimentation on internal datasets still show very strong performance and user value.
Design Reflections
LIDA aims to be reliable (always provide a valid visualization), accurate (always provide a high quality visualization), and fast (as few LLM calls as possible). Building a tool like LIDA naturally entails multiple experiments. Here are some of the design choices made along the way.
Managing Latency and Cost: To minimize latency and cost, each stage in the LIDA pipeline is done in a single LLM call. For example data summarization, goal generation, visualization generation etc are all structured as single parameterized calls to the model.
Reliability and Quality Tradeoffs with Prompt Scaffolds. An important distinction with how code/text is generated in LIDA, is that the LLM does not address tasks free form. Instead, each task is framed as a “fill-in-the-gap” style generation task with strict instructions to adhere to a provided scaffold. This is further supported by preprocessing (e.g., detecting date fields and parsing them correctly) and post processing steps for error detection and recovery (e.g., extracting code from verbose LLM responses). This ensures added reliably in generated output format. An important tradeoff to note here is that the model may only explore solutions that conform to the provided scaffold. An unduly restrictive scaffold won’t do. Overall, this process benefits from domain understanding of the task and creativity.
Structured Responses for better application design: For all tasks, the model is required to provide structured output with examples. E.g, asked to follow a json format for its responses. This makes parsing results and piping them to subsequent modules possible.
Iterative Prompt Improvement: We use the error rate metrics to better understand limitations of the scaffold and LLM prompts. For example, by iteratively tuning the scaffold and prompts (to address failed generations), we were able to reduce error rates from 15% to less that 3.5% in the single shot regime (same GPT3.5 model). With automatic repair (feeding errors and self evaluation back to the model), we can achieve close to zero error rates.
Limitations
Systems like LIDA that integrate LLMs have limitations. Some are described below:
LIDA may not work well for visualization grammars that are not well represented in the LLM's training dataset. Similarly, we will likely see improved performance on datasets that resemble example datasets available online.
Performance is bottlenecked by the choice of visualization libraries used and degrees of freedom accorded the model in generating visualizations (e.g., a strict scaffold contrained to only visualization generation vs a generation scaffold with access to multiple libraries and general code).
LIDA currently requires executing code. While effort is made to constrain the scope of generated code (scaffolding), this approach still requires a sandbox environment to execute code.
Conclusion
Overall, I believe we are only beginning to scratch the surface of how LLMs can supercharge the visualization authoring process, supporting users across multiple tasks. Importantly, as the underlying models improve, systems like LIDA will reap those benefits. There are many open opportunities in experimenting with hybrid user interfaces (direct manipulation + text + voice + x), evaluations across low resources visualization grammars, categorizing the limitations of LLMs for visualization, more extensive evaluation etc. All areas for future research.
Additional examples on visualization created by LIDA can be found here.
References
[1] Interaction Design for Systems that Integrate Image Generation Models: A Case Study with Peacasso . https://github.com/victordibia/peacasso
[2] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn
Ommer. 2022. High-resolution image synthesis with latent diffusion models. 2022
IEEE. In CVF Conference on Computer Vision and Pattern Recognition (CVPR).
10674–10685.[3] Nori, Harsha, et al. "Capabilities of gpt-4 on medical challenge problems." arXiv preprint arXiv:2303.13375 (2023).
[4] GPT-4 Technical Report, OpenAI https://arxiv.org/abs/2303.08774
[5] Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022. Highresolution image synthesis with latent diffusion models. 2022 ieee. In CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 10674– 10685.
How could we start using this in visualizing our own datasets? I have a 94 million record dataset sitting in Snowflake enterprise