
Multi-Agent LLM Applications | A Review of Current Research, Tools, and Challenges
Issue # 16 | Autonomous Agents are the next step in the evolution of LLM Apps. What is the state of the art, applications and current limitations?


Update: I wrote a book on “Designing Multi-Agent Systems” that you can buy now at https://buy.multiagentbook.com/ .

What is the difference between asking a machine (i) “tell me the stock price of NVIDIA today” vs asking (ii) “build me an iphone app that shows stock price for all the companies I care about” ?
Complexity.
LLMs of today (e.g., ChatGPT, LLAMA, etc), when given access to tools (e.g., external memory, a calculator, web search, code execution etc), become agents that can act on our behalf to solve tasks (like question i above). The LLM could write code (e.g., use the yahoo finance package to fetch stock price data), which can be executed to derive the answer.
For the second task (ii), there is significant additional complexity where a single agent might struggle. First, a detailed plan is required and must be executed in some specific order with retries where needed. Next, the task might benefit from perspectives or actions from multiple entities (e.g., ioS engineering, interface design, backend/api, testing etc); these perspectives and resulting actions need to be integrated into the overall solution. For a machine to accomplish this task, one potential approach, is to explore a group of agents (multi agent) that collaborate (with themselves and with humans) until the task is accomplished.
As we experience advances in LLMs, we envision a future where such groups of agents that help us with increasingly complex tasks. This view is not in isolation. The quote below from a recent article by Bill Gates (November 2023) offers a similar perspective on what a future of agentic tools could look like .
Excerpt from an article on GatesNotes.com
In the next five years, this […] will change completely. You won’t have to use different apps for different tasks. You’ll simply tell your device, in everyday language, what you want to do. And depending on how much information you choose to share with it, the software will be able to respond personally because it will have a rich understanding of your life. In the near future, anyone who’s online will be able to have a personal assistant powered by artificial intelligence that’s far beyond today’s technology.
Furthermore, recent research suggest that the use of multiple agents can improve reasoning and factuality (Du et al., 2023), as well as improve divergent thinking (Liang et al., 2023) - well known limitations of systems built with LLMs.
Given these observations, a multi-agent setup could be the next frontier for building increasingly capable systems.
TLDR;
This post evaluates the current state of affairs with multi-agent systems, covering the following:
Why Agents, or Multiple Agents ? - what do we stand to gain by exploring an agent or multi-agent setup?
What is the landscape of multi-agent frameworks (e.g., frameworks like AutoGen, CAMEL) and emerging startups/services (fixie.ai, lindy.ai). Definitly try out AutoGen.
What are the challenges associated with using multiple agents? - This includes control tradeoffs (autonomy vs deterministic behavior), evaluation challenges, as well as addressing privacy, security, and continuous learning within these systems.

Agents: What and Why?
Let us consider the following (complex) supply chain problem (in the diagram below) …

Is it possible for Roastery 1 to be exclusively used by Cafe 2? How would that affect overall cost?
To address this question, typically a supply chain expert, collaborating with other domain experts, would be required. If we envision a machine undertaking this task, several critical functions (see REACT paper [16]) must be executed effectively:
Reason: The initial step is to develop a plan [16, 21,22] of action that outlines the necessary steps that address the task. This plan must be comprehensive, accurate, efficient, and adaptable. An effective "agent" must be capable of reasoning through the various factors involved in the problem, considering information about locations, capacities, transportation options, costs, and potential obstacles. For instance, the plan may include 1. Understanding the current setup, 2. Gathering data, 3. Clarifying assumptions, and 4. Running financial analysis. 5. Generating a final plan.
Act: Each step requires specific actions. For example, step 1 may involve reading and summarizing documents on the current supply chain process; step 2: searching datasets on relevant topics and running database queries; step 3 may entail obtaining feedback from stakeholders such as the CEO, accountant, or other subject matter experts (human feedback) to verify the current plan; and step 4 might necessitate computation or data analysis, all culminating in a final report.
Communicate: Throughout the process, an adept agent must determine the most effective way to manage the flow of information across each step and associated entities (other agents or humans). For example, it must ascertain what context the subject matter experts should be aware of or which outputs from the previous steps are relevant to the financial analysis step.
So … what are agents?
Definitions vary, but based on the above, we can define agents as entities that can reason, act and communicate to solve problems.Multi-agent applications involve a group of agents, each ideally possessing diverse capabilities, such as language models, tools, and objectives, working collaboratively to solve tasks.
Along the way, it is also expected that these agents exhibit some level of autonomy and be efficient with the use of human feedback (i.e., they must be proactive, learn human preferences and context). In fact, their level of “helpfulness” is correlated with how well they can correctly address tasks with little or no human intervention, truly freeing us from the burden of many tasks.
Why Now?
Historically, the concept of agents acting on behalf of humans or groups of entities collaborating to address complex tasks is well-established. Research into agent-based systems has encompassed the study of robots, with a focus on path planning, robot navigation, and the Sense-Plan-Act paradigm. Additionally, multi-agent systems have been investigated in the context of human collaboration on tasks, which includes collective intelligence and crowdsourcing, as well as efforts to replicate human collaboration through artificial agents in group settings, such as swarm intelligence and network theory.
However, the development of agents has been limited by the lack of reasoning engines capable of adapting to context and synthesizing plans, tasks, and actions.
Recent benchmarks reveal that large foundation models, such as GPT-3.5 and GPT-4 etc, mark a significant improvement in the reasoning abilities of artificial entities. They provide a crucial missing component, thereby enabling new experimentation and advances in the development of truly autonomous multi-agent systems. These models signal the beginning of a new era for agents and multi-agent systems.
Multi Agent Systems
Do we truly need multiple agents? Or would a single agent setup (similar to the idea of GPTAssistants introduced by OpenAI, or implementations in LangChain) suffice? Over the last few months, I have spent time thinking through this, and my current argument is that some complex tasks have properties that lend themselves really well to a multi-agent solution approach.
Complex Tasks
In the introduction above, I allude to “task complexity”, as a potential driver for a multi-agent approach. But what properties make a task complex? The following list explores an initial set of such properties:
Task Decomposition
Requires planning, which involves breaking the task down into steps that must be completed successfully. This is a generally known and studied property from the robotics and planning literature [21, 22].Instructional Complexity
Instructions for complex tasks may be lengthy and underspecified (e.g., write a 100 page book with the following characters ; file my taxes etc), necessitating multiple iterations to build context and fully define the solution.
Lengthy instructions or context presents a significant challenge for single-agent systems due to known difficulties with long or complex instructions (LLMs struggle to follow instructions in the middle of long context [7]).
Theories from cognitive science also warrant a need for approaches that specifically improve performance on long context. For example cognitive load theory suggests that the human brain has a limited working memory capacity. Lengthy and underspecified instructions can overwhelm this capacity, leading to decreased comprehension and performance.By structuring instructions to minimize unnecessary cognitive load, we can improve task performance.Diverse Expertise
Benefits from the collaboration of multiple entities, each bringing diverse skills/expertise, tools, or perspectives to the task.
Emergent Solutions
Problems where the solution arises from the interactions among multiple agents, with the exposure to the outputs from previous steps and the state and process of each agent enhancing the solution. This property is inspired by observations in complex system theory1 where the overall behavior of a system emerges from the interactions of its parts. It is also inspired from Additionally, it incorporates insights from metacognition studies, which suggest that an agent's awareness and regulation of their own cognitive processes can significantly influence the problem-solving process. Metacognitive skills (which are challenging for single LLMs today [23,24]) enable agents to reflect on, evaluate, and adjust their strategies in real-time, leading to more adaptive and potentially innovative solutions within the emergent framework of multi-agent collaboration.
Autonomous Exploratory Problem-Solving
The task solution is not known beforehand, may take various forms, and results from exploring a vast search space (optimization). For these sort of problems it is more challenging to write deterministic pipelines (e.g., LLM prompts, specific tools), hence the need for agents that can self orchestrate (with some autonomy) to address the task.
Some examples of complex tasks are mentioned below :
Web Application Development
Build a web application to manage and standardize data for all contractors for the state of Hawaii. The data format must be backward compatible and also provide dashboards plus search to help answer critical questions, e.g., which contractors are on schedule, which are late, etc.; allow data sharing with other states and ensure SOC 2 compliance.
Supply Chain Analysis
Determine if Starbucks on Chancey Boulevard in Santa Clara can be serviced by the coffee bean Roastery on Clive Avenue in San Jose and analyze the cost implications.
Tax Filing for Multiple Entities
Create a detailed analysis with a final recommendation for a portfolio of three companies: an LLC in California, an S Corp in New York, and a startup in London. Assist with filing their taxes.
Slide Deck Enhancement
Review and enhance a slide deck to make it more interactive. Correct grammar, improve graphics, and apply appropriate animations. These tasks require careful planning, actions with outputs necessary for multiple downstream steps, and consultation with human experts for feedback.
From LLMs to MultiAgent Approaches.

LLMs can already solve many tasks that previous were only within the purview of human capabilities. But our current approach in training LLMs make them have blindspots - hallucination and reduced performance on taks that require multistep reasoning, logic or computation.
Agents (LLMs + Memory/Knowledge Sources + Tools) . Giving LLMs access to knowledge source helps ground responses (reducing hallucination), while giving them access to tools (e.g. a code compiler, apis etc) allow them address tasks like calculations, data processing etc.
However, many complex tasks (like the supply chain task in our running example above), a few properties
Multi-Agent Setup (Groups of Agents). A Multi-Agent approach enables “separation of concerns” where each agent can address a specific goal leading to improved results. Prior work suggests that multiple agents can help encourage divergent thinking (Liang et al., 2023), improve factuality and reasoning (Du et al., 2023), and provide validation (Wu et al., 2023).
In summary, for problems that are complex, the argument is that a multi-agent setup can improve performance.
A genuine problem-solving process involves the repeated use of available information to initiate exploration, which discloses, in turn, more information until a way to attain the solution is finally discovered.—— Newell et al. [9]
Research and Tools for Multi Agent LLM Systems
IMO, the multi-agent approach is still emergent and similar to the early days of tools like Theano/Lua/Tensorflow/Pytorch for building neural networks, we are beginning to see OSS frameworks aimed at enabling multi-agent application development.
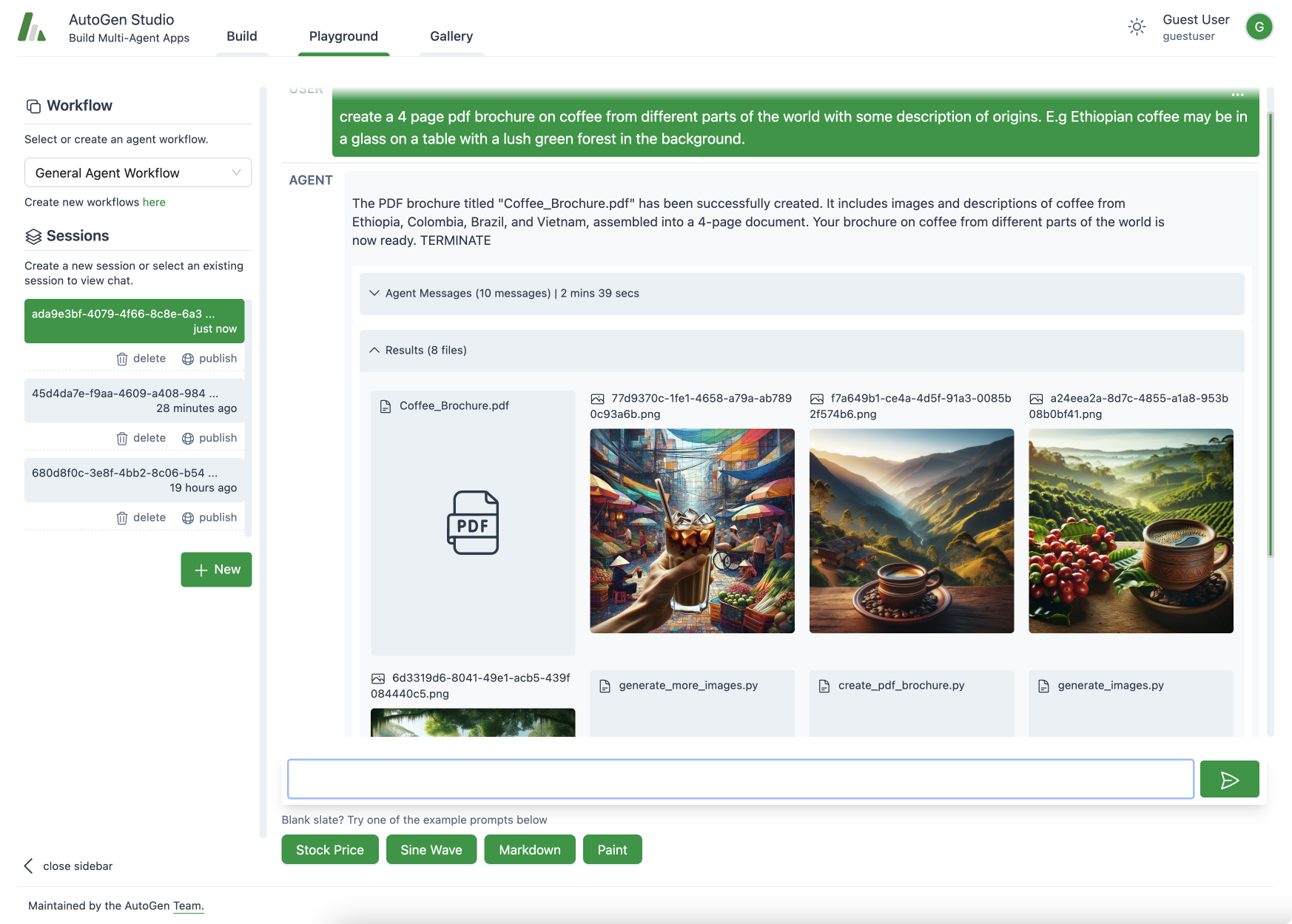
This section aims to briefly introduce AutoGen (a framework for building multi-agent applications. Disclaimer - I am a contributor to AutoGen) and also keep the reader informed on other related OSS projects:
AutoGen
AutoGen makes a few important decisions in terms of how it facilitates the design of multi agent applications
Flexible API for defining agents: AutoGen provides an API that is easy to use, supports Multi-Agent communication with (between agents as well as agents and humans)
Conversational Programming Paradigm: Agents and humans communicate via a shared message list which they both append to.
Ecosystem Integrations: Supports a growing list of ecosystem integrations. E.g., AutoGen supports multiple LLM providers, multimodal models and agents, low code tooling etc.
Other Multi Agent AI Frameworks
[Recommended] AutoGen: framework that enables the development of LLM applications using multiple agents that can converse with each other to solve tasks. Disclaimer: I am a contributor!
CAMEL: Communicative Agents for “Mind” Exploration of Large Scale Language Model Society
ChatDev: Explores the idea of agents collaborating towards writing software.
Langroid - Harness LLMs with Multi-Agent Programming.
Note that there are a few other OSS projects that focus on agents but have less emphasis on multiple agents collaborating towards a task. Some examples include:
LangChain Agents - A subset of Langchain where a language model is used as a reasoning engine to determine which sequence of actions to take and in which order.
LLAMAIndex Agents - An “agent” is an automated reasoning and decision engine. It takes in a user input/query and can make internal decisions for executing that query in order to return the correct result.
BabyAGI - A script for AI-powered task management system.
AutoGPT - A semi-autonomous agent powered by LLMs to execute any task for you
Several startups have begun exploring tools that incorporate a multi-agent approach to task resolution, where planning is executed and multiple agents collaborate to tackle these tasks.
Fixie.ai: A platform for building conversational AI agents that are designed to answer questions, take action, and live directly alongside your application.
Lindy ai: build a team of AI employees working together to perform any task.
Adept.ai: An AI teammate for everyone. Adept is building an entirely new way to get things done. It takes your goals, in plain language, and turns them into actions on the software you use every day.
Important Challenges of Multi-Agent Systems
Agentic systems hold promise, but they are also pose many challenges. Some of these limitations concern agents specifically, but others are common to all software systems and are exacerbated by an agentic approach. All these areas are actively being researched, with some mitigations already implemented in libraries like AutoGen.
Controllability (Autonomy vs Deterministic Behavior)
A tenet of multi agent problem solving is the promise of autonomy i.e., agents can device the right path to a solution with minimal supervision. However, an important tradeoff here is that the freedom to define the solution strategy (which may be efficient or costly) making it less likely that we can enforce fine grained control on the behavior of the system. It thus becomes hard to reason about the overall behavior of the resulting system i.e., some loss in deterministic behaviors.
It is evident that an effective framework for multi-agent development must offer the capability to establish and enforce reasonable constraints while still permitting autonomy and independent problem-solving. It should also offer tools that help developers reason about the expected behaviors of agents (e.g., via fast simulators, or profilers).
Evaluation: Measuring Task Completion, Reliability, Cost
Tasks that necessitate a multi-agent setup are often multi-dimensional, which makes evaluating the outcomes to accurately determine success quite challenging. E.g., consider the supply chain problem posed earlier where the solution includes complex financial analysis based on facts and figures. Even in cases where a solution can be validated, it is also crucial to quantify its reliability (e.g., failure rate per number of attempts) and its efficiency (resource consumption compared to an expert-tuned baseline).

There have been recent benchmarks (.e.g., GAIA [12], GPQA[13], TaskBench[25], AgentBench[26], AgentBoard[28], SWEBench[36]) that seek to curate truly agentic tasks that require access to multiple tools as well as multimodal capabilities. GAIA [12] proposes 466 real-world questions that require a set of fundamental abilities such as reasoning, multi-modality handling, web browsing, and generally tool-use proficiency. Answers are unambiguous and by design unlikely to be found in plain text in training data. Some questions come with additional evidence, such as images, reflecting real use cases and allowing better control on the questions. GPQA [13] proposes a challenging dataset of 448 multiple-choice questions written by domain experts in biology, physics, and chemistry where experts who have or are pursuing PhDs in the corresponding domains reach 65% accuracy, while highly skilled non-expert validators only reach 34% accuracy, despite spending on average over 30 minutes with unrestricted access to the web.
LLM Jailbreaks: Safety, Privacy and Security
LLMs and the tools they can interact with are vulnerable to a variety of security threats. Exploits such as "prompt injection" or “jail breaks” [17, 18,19, 20, 27, 29, 30, 31, 36] are vulnerabilities where an LLM is manipulated into unintended or malicious behaviors e.g., revealing confidential or secret information, generating harmful text etc.
What is a Jail break?
In the context of LLMs, attacks that elicit harmful, unsafe, and undesirable responses from the model carry the term jailbreaks [20]. Concretely, a jailbreaking method, given a goal G (which the target LLM refuses to respond to; e.g., ‘how to build a bomb’), revises it into another prompt P that the LLM responds to.
Some scenarios related agents include:
Privacy and Data Access Control:
Unlike traditional systems (e.g., databases) where granular access control rules can be strictly enforced, LLMs integrated into applications may require more thoughtful security paradigms. Consider the situation where an agent can act by making database requests given some end user instruction. There is the privacy risk that the agent can be “jailbroken” into making requests for data beyond the access boundaries for that user.
In such cases, it may be more effective to restrict an LLM's access to sensitive information altogether rather than instructing it not to disclose certain data. This principle also applies to other tools that LLMs might use.Code Execution: Consider an agent that acts by generating and executing code. Such an agent could be “"jailbroken” to exfiltrate sensitive information to an unauthorized server.
A possible security measure is to operate under the assumption that agents could behave in a hostile manner and therefore only allow it access to tools that have limited capabilities for misuse. An example is to sandbox code execution within a docker container, without the ability to send data externally.
Perhaps, the important takeaway here for developers is that, the introduction of LLMs as agents, greatly expands the potential for security vulnerabilities.
Responsible AI: Guardrails for Autonomous Agents
How can we efficiently implement guardrails for autonomous agents while ensuring that their autonomy and helpfulness serve the purpose of responsible deployment? It is crucial to ensure that the agentic paradigm, which enable machines to act on our behalf, do not introduce unintended side effects. This concern is significant because the actions of agents can lead to real-world consequences, e.g., an inadequate email response, incorrect information provided to stakeholders, errors in tax calculations, or incorrect job applications. How can we reduce the exposure of human welfare to these risks across all AI domains, and what new or existing policies can guide our practices? How do we ensure that the human reprises the right level of control?
Recent research have proposed tools to support visibility into agent behaviors [32, 38], harms that may arise from agentic systems [33] and strategies for governing such systems [35].
Continuous Learning and Memory
As agents address tasks, they may develop solutions to subproblems or seek feedback/help from humans to tackle these subproblems. When encountering the same subproblem in the future, they often repeat this discovery process, leading to significant inefficiency. At first glance, it appears that storing each subproblem and its solution for later recall might be a straightforward solution. However, in practice, several challenges emerge. These include determining how to identify subproblems and the level of detail at which they should be stored; assessing whether subproblems can be reused across different agents or organizational boundaries, along with any associated security implications; understanding if there are interdependencies among subproblems; and figuring out how to create generalized representations of a subproblem that can adapt to various contexts.
Tools such as Voyager [7] investigate this concept by implementing an agent in Minecraft that is capable of learning to write code (skills), which is then stored in a memory bank for future reuse.
Maintaining Personality and Focus
Agents based on Large Language Models (LLMs) can exhibit brittleness. This issue stems from the fact that core behaviors are defined by natural language instruction prompts (LLM system message) which function as soft constraints that guide response generation. As agents engage in interactions and share a common conversation history—such as in the AutoGen framework where agents can send and receive messages by maintaining a shared message history—they can "lose focus" on their designated roles or tasks. The CAMEL paper [14] discusses this challenge as “role flipping”.
Furthermore, as agents engage in extended conversations, they may forget earlier instructions [8]. While instruction prompting can help (e.g., reminding agents of of their roles), these agents must be driven by LLMs with strong instructions-following capabilities. Smaller models may not perform adequately without additional fine-tuning.
Efficient Orchestration
Orchestration refers to defining which agents address tasks, and how information or action sequences are executed towards solving a task. Finding the most efficient group or workflow of agents to solve the tasks is an important meta task. Does a human manually design/specify the list of agents or should be the optimal agent workflow be automatically discovered (via some optimization process) ? (E.g., Autobuild in AutoGen) . Furthermore , after workflow design, how can we effectively route the action reply space (which agent handless which part of the task)? Also, how do we manage communication patterns across agents e.g., do we impose constraints based on the problem domain or provide autonomy to these agents to define these constraints.
There might be opportunity to borrow ideas from many adjacent theoretical domains e.g., robotics and planning, swarm intelligence2, reinforcement learning, network theory3, actor network theory4 in deriving optimized orchestration approaches.
Task Termination Conditions (Infinite Loops)
When agents collaborate on tasks over long durations, determining the completion status of the task can be challenging.
This can lead to infinite loops of agent interactions when task completion is not well defined.
This also introduces new UX considerations on exploring the right way to both communicate agent intersection traces (the process the agents took) as well as some concrete summary of the task status and outcome.
AutoGen [1] provides termination conditions based on messages or custom logic defined in functions, which is beneficial for control. Both AutoGen and CAMEL utilize a maximum number of conversation turns to restrict conversation length. In practice, as agents navigate tasks, they will likely need more dynamic task control mechanisms. One potential approach is the idea of “baby sitter” models that can help rank or prioritize decision making at various points. E.g., models to rank multiple plans given the task, determine if a plan is succeeding or might benefit from early termination, or detect infinite loops which tend to occur. Small reward models [15] trained to encode expert user preferences can be repurposed to serve this role.
Conclusion
The promise of a future where agents can reliably help us with complex tasks (e.g., build entire software applications, file taxes, ) is both interesting and is possibly close. LLMs today could form the building blocks of such agents. When given access to tools (LLMs + tools) and when they work in groups, these agents could solve complex tasks that are out of reach today.
However, there are many open challenges, making this direction an active and interesting area of research.
Whats Next? I am currently experimenting with multi agent capabilities using AutoGen - an open source framework for building multi-agent applications and will be writing more on this. If you are working on any of these areas, consider contributing.

About the Author
If you found this useful, cite as:
Dibia, V. (2024)Multi-Agent LLM Applications | A Review of Current Research, Tools, and Challenges. Self-published on designingwithml.com.
Victor Dibia is a Research Scientist with interests at the intersection of Applied Machine Learning and Human Computer Interaction. Note: The views expressed here are my own opinions / view points and do not represent views of my employer. This article has also benefitted from the referenced materials and authors below.
References
Wu, Qingyun, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. "AutoGen: Enabling next-gen LLM applications via multi-agent conversation framework." arXiv preprint arXiv:2308.08155 (2023).
Wang, L., Ma, C., Feng, X., Zhang, Z., Yang, H., Zhang, J., ... & Wen, J. R. (2023). A survey on large language model based autonomous agents. arXiv preprint arXiv:2308.11432.
Du, Yilun, Shuang Li, Antonio Torralba, Joshua B. Tenenbaum, and Igor Mordatch. "Improving Factuality and Reasoning in Language Models through Multiagent Debate." arXiv preprint arXiv:2305.14325 (2023).
Liang, Tian, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Zhaopeng Tu, and Shuming Shi. "Encouraging Divergent Thinking in Large Language Models through Multi-Agent Debate." arXiv preprint arXiv:2305.19118 (2023).
Igniting Language Intelligence: The Hitchhiker's Guide From Chain-of-Thought Reasoning to Language Agents arxiv.org/abs/2311.11797
Liu, Zijun, et al. "Dynamic LLM-Agent Network: An LLM-agent Collaboration Framework with Agent Team Optimization." arXiv preprint arXiv:2310.02170 (2023).
Wang, Guanzhi, et al. "Voyager: An open-ended embodied agent with large language models." arXiv preprint arXiv:2305.16291 (2023).
Liu, Nelson F., et al. "Lost in the middle: How language models use long contexts." arXiv preprint arXiv:2307.03172 (2023).
Newell, Allen, John C. Shaw, and Herbert A. Simon. "Report on a general problem solving program." IFIP congress. Vol. 256. 1959.
Harrison Chase - Agents Masterclass from LangChain Founder (LLM Bootcamp)
Huang, Qian, et al. "Benchmarking Large Language Models As AI Research Agents." arXiv preprint arXiv:2310.03302 (2023).
Mialon, Grégoire, et al. "GAIA: a benchmark for General AI Assistants." arXiv preprint arXiv:2311.12983 (2023).
Rein, David, et al. "GPQA: A Graduate-Level Google-Proof Q&A Benchmark." arXiv preprint arXiv:2311.12022 (2023).
Li, Guohao, et al. "CAMEL: Communicative agents for" mind" exploration of large language model society." Thirty-seventh Conference on Neural Information Processing Systems. 2023.
Rosset, C., Zheng, G., Dibia, V., Awadallah, A., & Bennett, P. (2023, December). Axiomatic Preference Modeling for Longform Question Answering. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (pp. 11445-11475).
Yao, Shunyu, et al. "React: Synergizing reasoning and acting in language models." arXiv preprint arXiv:2210.03629 (2022).
Abdelnabi, Sahar, et al. "Not What You've Signed Up For: Compromising Real-World LLM-Integrated Applications with Indirect Prompt Injection." Proceedings of the 16th ACM Workshop on Artificial Intelligence and Security. 2023.
Mehrotra, A., Zampetakis, M., Kassianik, P., Nelson, B., Anderson, H., Singer, Y., & Karbasi, A. (2023). Tree of Attacks: Jailbreaking Black-Box LLMs Automatically. arXiv preprint arXiv:2312.02119.
Chao, Patrick, et al. "Jailbreaking black box large language models in twenty queries." arXiv preprint arXiv:2310.08419 (2023).
Wei, Alexander, Nika Haghtalab, and Jacob Steinhardt. "Jailbroken: How does llm safety training fail?." arXiv preprint arXiv:2307.02483 (2023).
Song, Chan Hee, et al. "Llm-planner: Few-shot grounded planning for embodied agents with large language models." Proceedings of the IEEE/CVF International Conference on Computer Vision. 2023.
Yuan, Quan, et al. "TaskLAMA: Probing the Complex Task Understanding of Language Models." arXiv preprint arXiv:2308.15299 (2023).
Momennejad, Ida, et al. "Evaluating Cognitive Maps and Planning in Large Language Models with CogEval." arXiv preprint arXiv:2309.15129 (2023).
Webb, Taylor, et al. "A Prefrontal Cortex-inspired Architecture for Planning in Large Language Models." arXiv preprint arXiv:2310.00194 (2023).
Shen, Yongliang, et al. "TaskBench: Benchmarking Large Language Models for Task Automation." arXiv preprint arXiv:2311.18760 (2023).
Liu, Xiao, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu et al. "Agentbench: Evaluating llms as agents." arXiv preprint arXiv:2308.03688 (2023).
Zeng, Yi and Lin, Hongpeng and Zhang, Jingwen and Yang, Diyi and Jia, Ruoxi and Shi, Weiyan. How Johnny Can Persuade LLMs to Jailbreak Them: Rethinking Persuasion to Challenge AI Safety by Humanizing LLMs.
Ma, Chang, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. "AgentBoard: An Analytical Evaluation Board of Multi-turn LLM Agents." arXiv preprint arXiv:2401.13178 (2024).
Wichers, Nevan, Carson Denison, and Ahmad Beirami. "Gradient-Based Language Model Red Teaming." arXiv preprint arXiv:2401.16656 (2024).
Zou, Andy, et al. "Universal and transferable adversarial attacks on aligned language models." arXiv preprint arXiv:2307.15043 (2023).
Shin, Taylor, et al. "Autoprompt: Eliciting knowledge from language models with automatically generated prompts." arXiv preprint arXiv:2010.15980 (2020).
Chan, Alan, Carson Ezell, Max Kaufmann, Kevin Wei, Lewis Hammond, Herbie Bradley, Emma Bluemke et al. "Visibility into AI Agents." arXiv preprint arXiv:2401.13138 (2024).
Chan, Alan, Rebecca Salganik, Alva Markelius, Chris Pang, Nitarshan Rajkumar, Dmitrii Krasheninnikov, Lauro Langosco et al. "Harms from increasingly agentic algorithmic systems." In Proceedings of the 2023 ACM Conference on Fairness, Accountability, and Transparency, pp. 651-666. 2023.
Russinovich, Mark, Ahmed Salem, and Ronen Eldan. "Great, Now Write an Article About That: The Crescendo Multi-Turn LLM Jailbreak Attack." arXiv preprint arXiv:2404.01833 (2024).
Shavit, Y., Agarwal, S., Brundage, M., Adler, S., O’Keefe, C., Campbell, R., ... & Robinson, D. G. (2023). Practices for Governing Agentic AI Systems. Research Paper, OpenAI, December.
Jimenez, Carlos E., John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. "Swe-bench: Can language models resolve real-world github issues?." arXiv preprint arXiv:2310.06770 (2023).
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery, Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, David Ha https://arxiv.org/abs/2408.06292
Dibia, Victor, Jingya Chen, Gagan Bansal, Suff Syed, Adam Fourney, Erkang Zhu, Chi Wang, and Saleema Amershi. "AutoGen Studio: A No-Code Developer Tool for Building and Debugging Multi-Agent Systems." arXiv preprint arXiv:2408.15247 (2024).
Complex System Theory https://en.wikipedia.org/wiki/Complex_system
Swarm Intelligence https://en.wikipedia.org/wiki/Swarm_intelligence
Network Theory https://en.wikipedia.org/wiki/Network_theory
Actor Network Theory https://en.wikipedia.org/wiki/Actor%E2%80%93network_theory
Great write up there Victor, where do you recommend one start from in this large landscape of agents and multi agents?
Great post, Victor! It would be interesting to know your thoughts on LangGraph and CrewAI