
How will AI Impact Software Engineering?
Issue #23 | How will software engineering change in the age of strong AI models that can write code and what should individual engineers and teams do to adapt?


Generative AI models can now write code. There is an uptick in AI-Assisted software engineering with tools like GitHub Copilot showing a 180% year-over-year adoption increase and revenue run rate of $2 billion over the last 2 years. From simple functions that an LLM can directly generate (reverse a string), to medium complexity apps that are now achievable via multi-agent systems (see Devin, GitHub Copilot workspace, AutoGen).

As a result of the seemingly expanding scope of what these systems can now do, many questions arise - Will AI replace software engineers? Will software engineering degrees still be relevant? How will the software engineering profession change?
This post will try address these questions by covering:
What coding tasks can generative AI models reliably handle today? What can they not do today?
How will the software engineering trade change?
What should individual software engineers and engineering teams do to adapt?
Along the way, I will reference notes from Steve Newman (founder of Writely, the startup that became Google Docs) who reflects on this issue in his April 2023 post - I’m a Senior Software Engineer. What Will It Take For An AI To Do My Job? I have also discussed some of the ideas below in a video podcast with Arstechnica and MongoDB in Jan 2024 - AI and the Evolution of Developer Experience [2], snippet from video podcast below.
What Do Software Engineers Do?
Well, depending on level of experience, we can simplify what software engineers do into the following 3 high level tasks:
Design/architect systems: . This includes thinking through the right components, the right levels of abstractions, the right interfaces and arguments being mindful of and documenting the tradeoffs pros and cons involved and the problem contextual needs for end to end systems. This could be for a small library such as LIDA that generates visualizations using AI models or an product e.g., a social networking platform like Twitter. Architecting systems involve decisions - when to use sync vs async/event-based methods, what streaming protocol, what database type is suitable (e.g., OLAP vs Analytical), how do I ensure the design is modular, extensible and future proof etc. The outcome of this exercise is typically some design document and some diagrams.
Write Code to solve simple and then complex problems.
An example of a simple problem may be to validate a string as json, a logging module to save data etc. A complex system might be a social network like Twitter with many components and dependencies. The deliverable might range from some function and an associated unit test, to a fully tested, reliable product improved based on feedback with millions of users.Fix bugs. Bugs come from many different sources. Some are straightforward to discern - the solution is right there in the error message (e.g., crash caused by a None value being read … you check for null and handle that gracefully). Others are wicked. e.g., the response from an external 4th party api silently changed in a way that failures are random, making it hard to perform root cause analysis.
Each of these tasks have simple and complex versions that map well to what a junior (e.g., writing code to solve simple problems or fixing small or minor bugs) vs a senior/principal engineer or teams (designing/architecting complex systems, building end to end products, maintaining and improving products based on feedback) would take on.
What Can Generative AI Do?
Today's capable Generative AI models (e.g., OpenAI GPT-3.5+, Google Gemini, Anthropic Claude 3.5) can interpret complex problem descriptions (prompts) and generate code solutions. However, due to their probabilistic nature, these models exhibit varying levels of proficiency across different tasks. To understand their capabilities, it's useful to view them along a spectrum of reliability:
High Reliability (today):
Writing functions/components: Generate correct code for small to medium-scale problems (e.g., creating a complete React page component with styling for customer data entry).
Code Refactoring: Restructure existing code based on provided guidelines.
Bug Fixing: Identify and resolve minor to moderate issues in code.
Medium/Low Reliability (today)
Niche/New Problems:
Today's models excel at tasks that exist in its training dataset (in-distribution). See similar note on this by Yann LeCun. For example, it can reliably write sorting algorithms or build React components with TailwindCSS. However, quality degrades for niche or out of distribution tasks. For example implementing algorithms but in a non-mainstream or internal programming language; developing UIs in less common frameworks (e.g., Rust), writing efficient CUDA kernels for custom or new operations etc.Cognitive Leaps
In addition, problem settings that require cognitive leaps (perhaps in the presence of new information or feedback) continue to be challenging for LLMs. For example, LLMs might unreasonably stick to an incorrect position primarily because that information already exists in its context. For example, if an LLM is told the sky is black early within a multi-turn conversation, it may stick to this position despite feedback. This can be relevant to problems where a given course of action is unfruitful and needs to be abandoned.Complex End-to-End Systems
Models by themselves struggle to address tasks that require extensive context and iterative processing such as building an entire software product. The system must design and update the system architecture, integrate feedback, iteratively addressing complex bugs each with intricate dependencies while respecting contextual nuances.
To give a concrete example, while I was at Cloudera, the frontend application code base for our core machine learning product had portions of it written in Angular, React, and multiple component libraries. This complexity arose from team evolution and historical decisions (original version written in Angular, some glue code to enable interoperability as part of a long term transition to React functional components). Engineers working on this codebase needed to be aware of this context (usually by discussing with other engineers with tenure) who knew what could be safely removed, the correct order for rewriting components, and potential side effects of changes. Tasking an AI model to implement a new feature in such an environment would likely lead to errors due to a lack of deep contextual understanding - making it challenging.
Steve similarly talks about the choice of a database (Big Table vs an internal solution at Google at the time) for the Google Docs product, how he only arrived at the right choice by reading lots of design documents, weighing pros and cons, speaking with individuals etc. and how such a choice would be difficulty to pose to an AI model.
Note: While AI models themselves fall short in the ways described above, early results indicate a multi-agent approach could address these issues. Frameworks like AutoGen simplify the development of these systems and tools like Devin and GitHub Copilot workspaces illustrate what is possible today.

How Will Software Engineering Change?
In my opinion, the question "How will software engineering change with advances in AI?" is perhaps one of the more consequential matters for our profession. I think we can expect two main types of changes. First, we'll see technical changes directly affecting the core aspects of software development. In addition to Software 1.0 (code, rules), Software 2.0 (ML algorithms learning from data), we will see more advanced Software 3.0+ paradigms (prompting and agents). Second, we'll likely see non-technical changes throughout the software engineering ecosystem. These include shifts in developer roles and required skill sets, adaptations in software development processes (focus on integration of, verification, benchmarking of AI generated code), changes in documentation practices to improve AI-generated code, AI models influencing technological choices, the potential emergence of AI model marketplaces, etc.
From Software 1.0 (writing code to solve problems) to Software 3.0+ (defining agents that address tasks)
Advances in machine learning and generative AI have introduced potentially new ways to create software that solves user problems. In my upcoming book, "Multi-Agent Systems with AutoGen," I describe this change across three phases:
Software 1.0: Traditional software development where we write code and rules that are compiled to solve problems.
Software 2.0 (popularized by Andrej Karpathy's article): We apply ML algorithms to extract rules directly from data to solve problems.
Software 3.0+: This phase is driven by generative AI models and consists of two steps:
Prompting: We write natural language instructions that elicit solutions from capable pretrained generative AI models. Tools like GitHub copilot are an implementation of this approach.
Agents. We define agents (configurations of models with access to tools) that can collaborate to solve dynamic, complex problems.
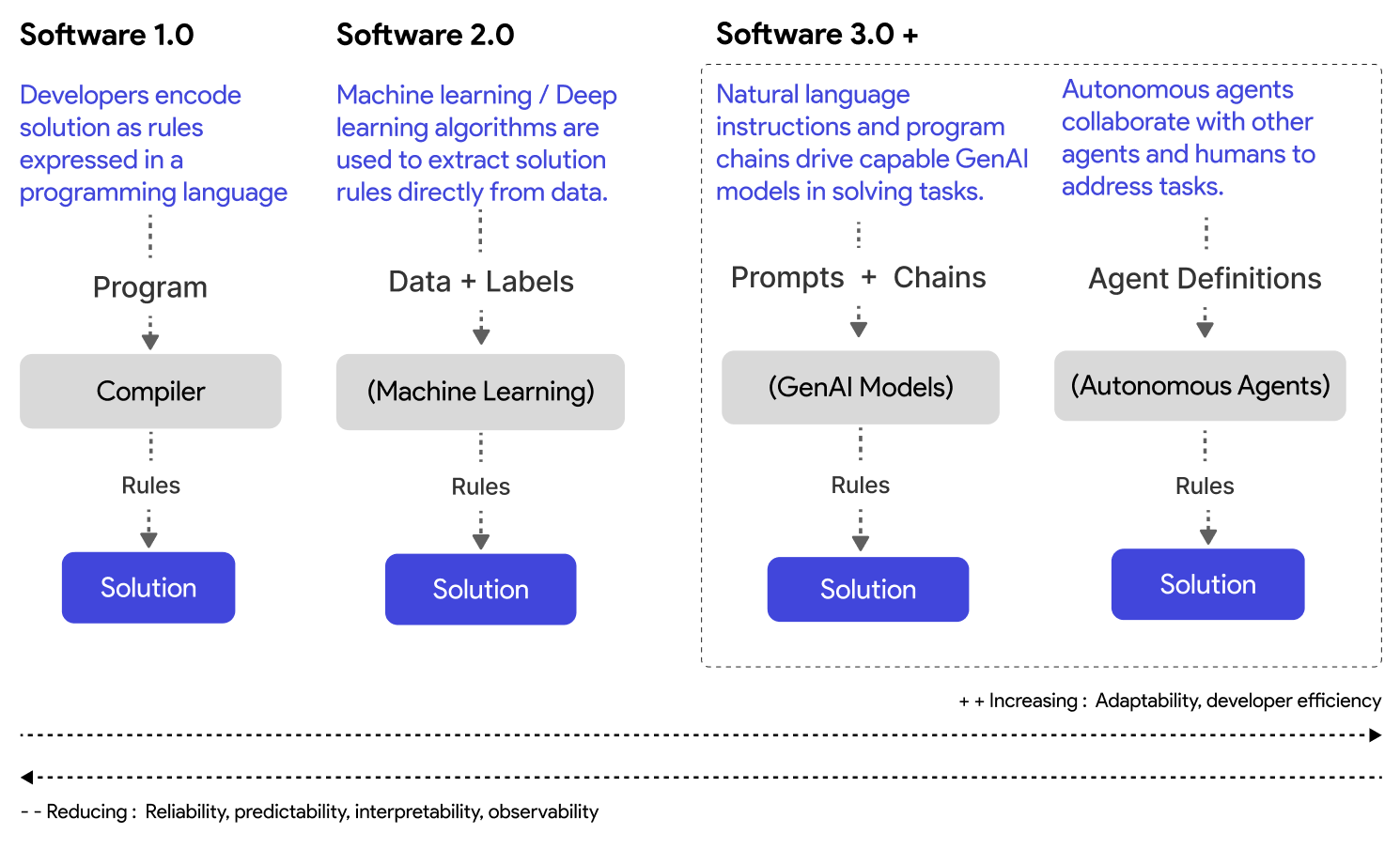
Importantly, there are reliability tradeoffs introduced with probabilistic AI/ML models. As systems become capable of independently addressing tasks (reducing developer or user effort), the complexity and probabilistic nature of models introduce reliability issues. It is likely that future software systems will work best with a careful combination of approaches from Software 1.0, 2.0, and 3.0.
A Shifting Focus to Verification, Benchmarking, Red Teaming:
The cornerstone of software development has long been the pursuit of reliable, bug-free code. This goal has spawned entire sub-industries and processes, including code peer review, software testing, and CI/CD pipelines. Many of these processes are deeply human-centric, built around interpersonal interactions and reputation systems. As AI and generative models become potential contributors to the development process, we will need to adapt these reliability processes to verify reliability of automatically generated code.
This necessitates the development of new verification methods which may take the form of direct correctness checks tailored for AI outputs; AI reputation systems; Human-in-the-loop integration, as demonstrated by GitHub Copilot workspaces etc.
A considerable amount of energy will be spent on systems to verify AI output, benchmark performance (e.g., HuggingFace LLM leaderboards and ScaleAI SEAL benchmarks) and red teaming (see the Microsoft PyRIT tool for finding risks in models) to understand scenarios where models fail or can result in catastrophic errors.
The term red teaming has historically described systematic adversarial attacks for testing security vulnerabilities. With the rise of LLMs, the term has extended beyond traditional cybersecurity and evolved in common usage to describe many kinds of probing, testing, and attacking of AI systems. With LLMs, both benign and adversarial usage can produce potentially harmful outputs, which can take many forms, including harmful content such as hate speech, incitement or glorification of violence, or sexual content.
Microsoft Learn - What is Red teaming
Writing Design Docs for Humans AND Machines:
Traditionally, design documents have been written for human developers. However, with the rise of Generative AI (GenAI), we now need to consider both human and AI audiences.
In the Software 3.0 paradigm, it is plausible that humans describe systems they are interested in within design documents that agents consume these documents to build these systems.
For GenAI to address complex problems effectively, it must understand context and follow specifications laid out in design documents. This presents a challenge due to subtle differences between human communication and effective AI prompts. For example, current Large Language Models (LLMs) can be sensitive to information position within documents. Important instructions may need specific placement or emphasis for AI processing, unlike human-oriented documentation where key information can be spread throughout.
To bridge this gap, we should explore:
Structured formats catering to both humans and AI
Standardized emphasis techniques effective for both audiences
Tools for translating between human and AI-oriented documentation styles
IMO, in addition to existing research on automated prompting (e.g. DSPy, etc) more research is needed to understand how best to craft design documents that work well for both humans and AI agents.
Developer Habits Driven by Generative AI
As developers increasingly adopt generative AI, it's likely to influence coding habits and technology choices. This is in fact similar to how recommender algorithms are altering social dynamics (who we follow on Twitter, information we are exposed to etc) [3]. This trend is driven by two key factors:
Model Recommendations: When prompted to complete a task, AI models may default to popular technologies. For instance, when asked to plot a chart, a model might suggest Python with Matplotlib, potentially steering developers away from alternatives like TypeScript with Plotly.js.
Model Performance: AI models tend to perform more reliably with widely-used technologies due to their prevalence in training data. For example, an LLM might generate React components with fewer bugs than Svelte components, inadvertently encouraging React adoption by developers that observe these discrepancies.
This bias towards established technologies can be problematic, as it may hinder the adoption of newer, potentially superior solutions.

Model and Data Marketplaces
To address the challenge of Generative AI models “"favoring” established libraries/tools, we can envision the emergence of marketplaces aimed at enhancing AI models' performance for specific products. Two primary approaches are likely:
Training Data: Companies could offer curated datasets (potentially augmented with synthetic data) for model providers to incorporate into pre-training or fine-tuning processes.
Model Adaptors (LORA): Providers might develop LORA (Low-Rank Adaptation) adapters that can be easily integrated with existing models to improve performance for specific tools.
These marketplaces would enable interested parties to contribute artifacts that optimize AI models for their products. This could help level the playing field for newer or niche technologies, ensuring they receive fair consideration in AI-assisted development environments.
Junior Engineer Jobs Will Evolve
Our previous observations on what AI can do today suggest that AI excels at small, compact tasks with high reliability—tasks typically assigned to junior engineers. Consequently, we may see junior roles pivot towards AI integration, verification, benchmarking, and red teaming as discussed earlier.
However, this shift presents a conundrum. If junior engineers aren't writing code or building systems from the ground up, it may interfere with the traditional learning path that develops them into senior engineers. In addition, this hands-on expertise is crucial for effectively creating the verification and benchmarking systems needed in an AI-augmented development environment.
As the industry adapts to these changes, finding new ways to cultivate deep technical understanding and problem-solving skills in early-career developers will be critical. This may involve reimagining software engineering education and creating novel on-the-job training approaches that blend AI-assisted development with foundational coding experiences.
Sadly, I am increasingly of the opinion that Junior engineer roles will go away entirely.
See this article.
The Great Displacement Is Already Well Underway
I don’t think my story is unique, I think I am at the early side of the bell curve of the coming social and economic disaster tidal wave that is already underway and began with knowledge workers and creatives. It’s coming for basically everyone in due time, and we are already overdue for proposing any real solution in society to heading off the worst of these effects.
What Should You Do About it?
Given all the changes that might occur, what can individual engineers, engineering teams and organizations do?
