
Agentic Noise: How AI Agents Can Break the Delicate Balance of Human Attention
Issue #60 | When AI Agents Flood One Side of a Platform, Everyone Loses

Most digital platforms today operate as two-sided markets. YouTube has creators and viewers. LinkedIn has posters and readers. Academic publishing has authors and reviewers/readers. Job boards have applicants and recruiters. Social media has people sharing life updates and friends (or strangers) consuming them.
These platforms evolved equilibrium mechanisms - rate limits, ranking algorithms, capacity constraints - all calibrated around a basic assumption: humans on both sides. Humans produce content at human speed, and humans consume it at human speed. There is an implicit contract in there that makes everything work.
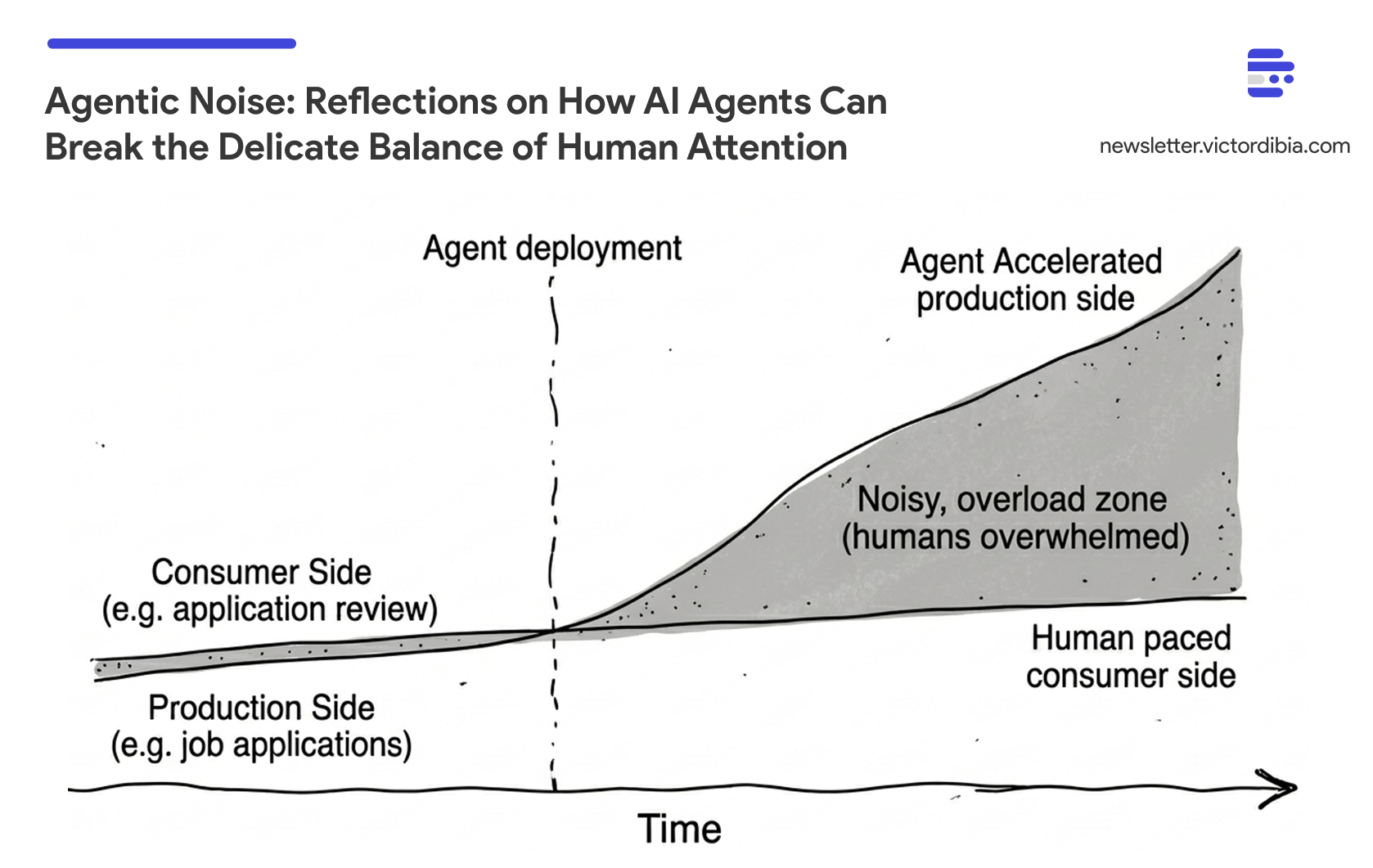
As AI models become more capable (AI agents that can act with some autonomy), there is a real chance that poorly considered AI agent (assymetric) deployments break this balance. In Designing Multi-Agent Systems, I introduce the concept of agentic noise to capture this phenomena.
Agentic Noise: When AI agents accelerate one side of a platform while the other remains human-paced, breaking the assumptions underlying the system’s design.
As we all deal with how our respective domains will change with AI, this post discusses some dimensions of the relevant issues:
What are the current examples of asymmetric AI acceleration? (job markets, academia, social media, publishing, children’s content)
What happens when platforms respond with AI on the consumption side too? (the arms race trap - symmetric acceleration without welfare gains)
What needs to change? (platform-level coordination mechanisms, builder responsibility for platform balance)
This post draws on ideas from Chapter 13 of Designing Multi-Agent Systems, which covers agentic noise, platform imbalance, distributed responsibility, emergent risks, and practical security frameworks for autonomous agents. Grab the book on Amazon or get the digital PDF.

Examples of Producer / Consumer Imbalance
Each example below follows the same pattern: agents accelerate one side, the other side scrambles to respond, and the resulting race inadvertently degrades the platform.
Job markets. AI application tools let candidates submit hundreds of tailored resumes per day. Recruiters responded with AI screening - and 19% report it has filtered out qualified applicants. The arms race feeds itself: applicants use AI to tailor resumes to job descriptions, so employers receive resumes that are increasingly similar, disrupting matching tools designed to differentiate them. The result is a trust/signal breakdown on both sides, with a federal class-action lawsuit (Mobley v. Workday) now testing whether AI screening tools can be considered legal “agents” of the employer. Some employers are eliminating resume requirements altogether, shifting to skills-based hiring because AI has rendered polished documents indistinguishable (low signal).
Academic research. I wrote about this in detail - the numbers tell the story. NeurIPS submissions jumped from ~9,500 in 2020 to over 23,000 by 2025. Systems like AI Scientist-v2 have already produced papers that passed peer review at top conference workshops. And now the review side is AI-accelerated too: at ICLR 2026, 21% of peer reviews were found to be fully AI-generated, with over half showing some AI use. Both sides are now agent-driven: agents writing papers, agents reviewing them. Meanwhile, organized “paper mills” use AI to generate fraudulent publications at industrial scale, and AI detection tools struggle to keep pace.
Social media and content platforms. LinkedIn feeds fill with AI-polished posts. YouTube surfaces AI-generated videos optimized for engagement but empty of substance. Platforms have responded with AI moderation - and YouTube’s version has become a cautionary tale. In 2025, YouTube terminated 12 million channels via automated enforcement. Legitimate creators get caught in the dragnet - tech tutorials flagged for using words like “bypass,” entire channels terminated with template responses - while sophisticated bad actors game the system.
Book publishing. As the author of Designing Multi-Agent Systems, this one has been rather interesting! Several bestselling books in my category on Amazon have the veneer of legitimacy - hundreds of reviews pushing them to the top of rankings. However, a cursory review of the 1-2 star reviews and you find a pattern: multiple independent readers calling out the same substantive problems. Not cosmetic complaints (”packaging was damaged”) but correlated indictments of actual content quality, often labelled as AI slop. These books sit at #1 while readers call them garbage.
Note: I think elegant writing and technical content can be authored with AI. But asking ChatGPT to generate pages of disconnected random content bundled together as a book is what readers are increasingly concerned about. I have done some deeper research on this topic and will share more soon.
Children’s content. I have a six-year-old son and he does get some screen time. Even on YouTube Kids - supposedly age-appropriate - there are hours of AI-generated videos. Knock-off Pokemon content with no storyline, no lesson, no careful design. Just visually addictive spinoffs engineered to capture attention rather than deliver entertainment or learning. Researchers have dubbed it “Elsagate 2.0” - AI-generated content targeting children at scale. Over 20% of videos recommended to new YouTube users are AI slop, with slop channels collectively accumulating over 63 billion views. Early-childhood experts warn that AI slop distorts children’s developing understanding of truth and reality. YouTube CEO Neal Mohan has acknowledged this as a 2026 priority - but many families have already moved to subscription services like Disney+ to avoid the recommendation engine entirely.
GitHub / OSS software. Most OSS repo report 100s of drive by commits with proposals like vouch - A community trust management system to ensure only individuals with some level of established trust can contribute to OSS project. Its a bit ironic. OSS helped jump start many a career - everyone has that first contributor story. With eroding trust
The Broken Signals Problem
In many of the examples above, there is the feeling that platforms should step up and address the issue. A key challenge here is that metrics we relied on to navigate the internet are now broken.
Views can be bot-driven. Comments can be AI-generated. Reviews can be manufactured at scale. The signaling infrastructure that humans built to navigate content is can now be gamed at machine speed.
This also creates an asymmetry in awareness. As someone who works in AI, I can often spot AI-generated responses to my LinkedIn posts. I can identify AI-generated YouTube videos and choose to save my attention. This is not necessarily the case for the majority of internet netizens today (kids inclusive). Their attention is consumed without their knowledge or consent. They engage with content that looks real, that has the social proof of engagement, but that was never created with their interests in mind.
The platforms themselves face a fundamental measurement problem. Their ranking algorithms optimize for engagement metrics that agents can now manufacture. The internal signals that determine what gets recommended to humans are being corrupted at the source.
Symmetric Acceleration Doesn’t Fix It
Even when symmetric acceleration works, it doesn’t necessarily improve human welfare. If AI agents write papers and AI agents review them, does that produce better research - or just higher-volume churn? When the credential was designed to signal human expertise, what does it mean when neither expertise nor effort is required to obtain it?
Software engineering is the latest example. AI coding agents generate pull requests at scale, making human code review a bottleneck. Anthropic’s response: Claude Code Review, a multi-agent system that reviews AI-generated code for $15-25 per PR. As PC Gamer put it: “so you don’t even need to check all of your own AI slop.” AI writes the code, AI reviews the code, and the human pays $25 to be removed from the loop.
At some point - AI generating content, AI generating comments, AI recommending it to other AI - all human value is lost. The question isn’t whether we can automate both sides, but whether we should.
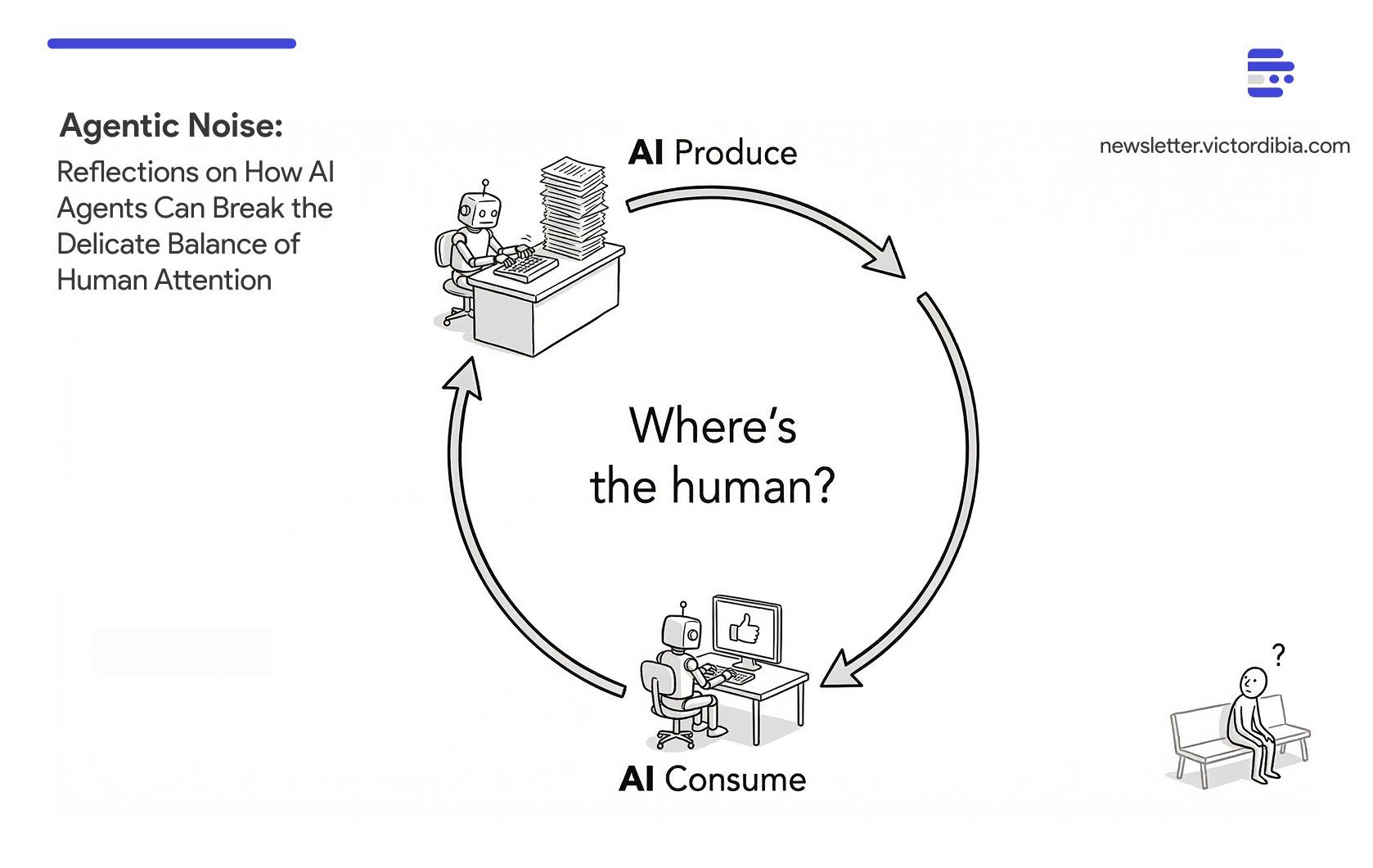
What Needs to Change?
There are no clean answers here. But a few directions seem clear.
For platforms: Engagement metrics are no longer reliable quality signals, but the alternatives are hard. “Provenance-aware ranking” sounds good until you remember that reliably detecting AI-generated content is an unsolved problem. Mandatory disclosure (as the EU AI Act attempts) shifts the burden but depends on enforcement. Some platforms have natural levers - conferences can perhaps raise submission fees, appointment systems can enforce identity verification - but open platforms like job boards and social media face genuine design tradeoffs where every intervention has collateral damage.
We’ve solved versions of this before. Spectrum allocation and robocall regulations both exist because unconstrained automated use degraded shared infrastructure. As I argue in the book:
From Designing Multi-Agent Systems, Chapter 13:
“When collective deployment degrades platform value for everyone, coordination mechanisms like rate limiting or platform quotas may become necessary, similar to spectrum allocation or robocall regulations.”
Agentic noise is the same class of problem, and it may require the same class of solution.
For builders of AI agents: Consider the impact on platform balance, not just the business value to the producer side. This is admittedly hard to operationalize - no individual organization can fix a collective action problem through restraint alone. But at minimum, asking “what happens to the humans on the consumption side when we deploy this?” should be part of the design process.
The excitement around agent capabilities is warranted. But what is the point of a #1 bestseller that readers call garbage? What is the value of a YouTube Kids feed full of AI-generated content no human designed for children? What do we gain from academia overrun by AI-generated and AI-reviewed papers?
