
Getting Started with AutoGen - A Framework for Building Multi-Agent Generative AI Applications
Issue # 17 | Understand key concepts with AutoGen and write your first multi-agent GenAI app!


In a previous article, I discussed the idea of multi-agent apps, how complex tasks might benefit from multi-agent solutions and challenges that arise. In this article, the goal is to delve deep into how we might implement such apps using the AutoGen framework. All code shown in this post is available in this accompanying notebook.
Feb 4, 2025: Edit, there is an updated version of AutoGen (v0.4) with an improved low-level and high level api. Learn more here.


TLDR;
What is AutoGen ?
Agent Definition
Conversational Programming
Task Termination
Basic Example (stock prices visualizations). Code notebook in here.
Deterministic vs Autonomous Workflows (pros and cons)
FAQs and Resources
https://newsletter.victordibia.com/p/a-friendly-introduction-to-the-autogen
A paper on AutoGen Studio is below:
Dibia, Victor, et al. "AUTOGEN STUDIO: A No-Code Developer Tool for Building and Debugging Multi-Agent Systems." Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2024.Definitions
For simplicity, this post will utilize the following definitions:
Model (LLM or LMM): A large language model (LLM or large multimodal model (LMM) that is used as a “reasoning engine” for generating text (or code) in response to some task prompt. Examples of LLMs include GPT4, Gemini Pro, LLAMA, Mistral etc
Agent: An entity that wraps an LLM, and can act via access to tools (e.g., apis, memory, code execution abilities) to address tasks.
Workflow: A configuration that defines a group of agents and how they communicate/interact to solve a task.
Complex Task: A task that requires multiple steps, may have multiple solution paths, require diverse expertise, involve actions with interdependencies across steps. An example - “Create an Android app to display stock price”. This would require steps in designing an interface, writing code, compiling code, testing etc with dependencies.
What is AutoGen?
AutoGen is an Open Source (MIT License) framework for building multi-agent applications. In this context, 'multi-agent' refers to a group of agents (LLMs equipped with tools) that collaborate, communicate, and act collectively to solve a task.
For example, given the task “show me a plot of the NVIDIA stock price in the last year”, we need the agents to explore a few steps:
devise a plan (e.g., use an api like the yahoo finance api to query data for the last year, use a framework like matplotlib etc to plot the data, save the resulting image to disc),
implement that plan (e.g., write python code that connects to yahoo finance, plots and saves chart),
execute the plan (e.g., execute the code, recover from errors iteratively) and
return a summary of the final result (text or chart).
Now, a seasoned engineer could possibly create a manual pipeline to address each of these steps. However, building pipelines for many variations of these sort of tasks can be tedious and resource intensive (engineer hours). The ability to specify a task and receive results from a group of agents can offer significant savings in effort.
This is where tools like AutoGen aim to help - by making it easy to define groups of agents that can execute multiple steps towards solving a complex task.
Why AutoGen ?
TLDR; AutoGen offers several unique benefits:
Conversational Programming: Defining agents and getting them to collaborate via conversation.
Autonomous Workflows: AutoGen has first-class support for autonomous and semi-autonomous workflows, beyond traditional chains of LLM agents.
Support for Human Input Mode: First class support for human intervention/feedback within agent conversations.
A Code first approach to agent action: In terms of how agents act, the AutoGen implementation heavily biases towards generating and executing code. This also includes agents being able to call pre-registered functions or write code that is subsequently executed.
Agents and Code Generation
Code execution introduces a non-linear aspect to an agent's abilities. An Agent that can write (or retrieve) and execute arbitrary code to accomplish arbitrary tasks, in theory, is more expressive/capable compared to an agent that knows , for example, how to use a fixed suite of tools.
Being able to formulate tasks as code, execute the code and then act on the output of that code (e.g., use the output of the code or repair and retry to address errors) in a continuing conversation enables solutions that can adapt to fit the task parameters.
Key Concepts with AutoGen
AutoGen enables multi agent applications by providing an API to define agents and then getting them to collaborate by sending/receiving messages as part of a conversation that terminates when the task is completed.
Agent Definition
At its core, AutoGen provides a base ConversableAgent class (the name is a nod to the use of conversations as the format for agent communication). A list of important parameters to the ConversableAgent Class are listed below:
system_message: System message useful for steering core agent behaviors
is_termination_msg: function to determine if a message terminates the conversation
max_consecutive_auto_reply: maximum consecutive auto replies
human_input_mode: determines when to request human input (e.g., always or never or just before a task terminates)
function_map: mapping names to callable functions. This wraps the openai tool calling functionality
code_execution_config: configuration for code execution
llm_config: configuration for LLM-based auto reply
AutoGen and Responsible AI
The AutoGen implementation stands out in its provision of the human_input_mode parameter which enables human feedback as part of the agent conversation towards solving a task. At anytime, the user may provide feedback (which is written to the message history) or may terminate the task.
AutoGen provides other convenience classes with slightly different parameters.
UserProxyAgent: UserProxyAgent is a subclass of ConversableAgent configured with `human_input_mode` to ALWAYS (the agent will prompt for human input every time a message is received) and `llm_config` to False (it will not attempt to generate an LLM-based response). However, code execution is enabled by default - this agent will execute code contained in messages it receives (mirroring what an actual user might do when they receive suggested code generated by an LLM).
AssistantAgent: AssistantAgent is a subclass of ConversableAgent configured with a default system message designed to solve a task (see screenshot below) with an LLM, including suggesting python code blocks and debugging. `human_input_mode` is set by default to "NEVER".

The default assistant agent message. GroupChat: GroupChat is an abstraction to enable groups of ConversableAgents to collaborate on a task, with some plumbing to orchestrate their interactions (e.g., determining which agent speaks/acts next), max rounds in a conversation etc. GroupChat is wrapped by a Group
GroupChatManager object which inherits from the ConversableAgent class.GroupChat: A container class for specifying properties of the groupchat e.g., a list of agents, speaker_selection_method
GroupChatManager: This class is necessary as it inherits from the ConversableAgent class which some differences. It takes in an additional GroupChat parameter (above), with some modifications to its behaviour. Specifically, when it receives a message, it broadcasts it to all agents, selects the next speaker based on the groupchat policy, enables a turn for the selected speaker, checks for termination conditions , until some termination condition is met.

Conversational Programming.
In AutoGen, each agent can send or receive messages via a send and receive method. Implementation wise, for each agent, a list of messages is maintained. Sending a message to an agent involves calling its 'receive' method, which appends the message to its message list. This list of messages maps very nicely to the message history object that is typically used with chat-finetuned models (see the OpenAI ChatML format).
When a message is received, the agent acts on it by running a list of registered reply functions. By default, each ConversableAgent can respond using an LLM, executing code in the message it received, checking for termination conditions or via some custom reply function.
LLM Reply Function : A reply function may be a call to an LLM. Note that the prompt to this LLM call contains the history of messages the agent has received so far, allowing the LLM generate relevant responses. The LLM reply is run by default if the agent is configured to have access to an LLM (llm_configuration).
Code Execution Reply Function: An agent configured with some code execution configuration (e.g., using docker, or a specified work directory) may extract code (if available) in the message it receives and then execute that code.
Termination Conditions and Human Reply: This reply function checks for conditions that require the conversation to be terminated, such as reaching a maximum number of consecutive auto-replies or encountering a termination message. Additionally, it prompts for and processes human input based on the configured human input mod
Custom Reply Function: Developers may specify custom reply functions that get executed when an agent receives a message. Examples include writing the received message to a socket, keeping some internal log etc.
Importantly, each reply is then “sent” to the calling agent (and you guessed it, by calling its receive method). Note that the output of the reply function gets added to the shared message history. This is important as it gives each agent visibility into the state of the task.
We will refer to the practice of interleaving conversation messages with logic to act (execute code) as conversational programming.
Task Termination
As the conversation progresses i.e., messages are sent, received, responses generated, code executed, the task may get solved, and we need some method or criteria to end or terminate the conversation. AutoGen handles this in a few ways:
is_terminate_msg: each agent has an `is_terminate_msg` parameter which is a function that must return a boolean indicating if the agent should terminate the conversation based on some condition. A common pattern here is to
Steer agent behavior (via system message) to output a TERMINATE string as the last word in its response when the task is judged to be complete/addressed. See the default AssistantAgent message above.
write an is_terminate_msg function that checks for TERMINATE as the last word in the response.
Note that as the designer of the agent, you can modify this behavior to produce more reliable outcomes or to fit the capabilities of the underlying models.
max_consecutive_auto_reply: The conversation ends when an agent has reached this maximum number of responses.
Common Agent Workflow Patterns in AutoGen
While agents in AutoGen can be composed into a very long list of complex configurations (hierarchical, custom orchestration etc), perhaps the two most common workflow patterns with AutoGen are listed below:
Two Agent Workflow: In this workflow, a UserProxy agent and an AssistantAgent converse to solve a user task.
This workflow is suitable for tasks of medium complexity e.g., can be addressed by a single main planner + executor. For example, the stock price example above.
Two Agents? Why Not One?
Well, if you think of a developer working with an LLM in a chat interface, the workflow typically resembles an interactive loop where the user states their task, the LLM provides a response (e.g., directives, explanations, code to be run), the user acts on this (e.g., provides feedback, runs the code and reports on the results etc) etc., until the task is solved. The Two Agent workflow attempts to mirror this exact type of loop, but autonomously. The UserProxy replicates activities that an actual user might perform in the loop (e.g., state the task, execute generated code and report on results, provide feedback) while the AssistantAgent performs activities that an LLM might focus on in the loop (e.g., reason over conversation state to generate answers or code).
GroupChat: A setup where a group of agents converse to solve the task.
The group interaction is managed by a GroupChat object.
This workflow is beneficial for use cases where it is expected that multiple agents bring diverse perspectives to addressing a task with some orchestration. These agents are “orchestrated” by a GroupChat manager that determines which agent acts are each step in the task completion conversation (this is configurable with settings such as auto, round_robin, random etc). An example task here may include writing a software application where a designer agent may work with a coder agent, an interface design agent and a code quality control agent to iteratively write and refine some code.
AutoGen is flexible, and can be configured to support more complex patterns (e.g., heirarchical chat, nested chats etc). For a full overview of supported patterns and examples, see the AutoGen paper [2] and documentation.
Getting Started - Installation, LLM Configuration , Basic Example
All code shown in this post are available in this notebook. Feel free to follow along by running cells in the notebook.
In this section, we will explore a simple example to getting started building with AutoGen. We can break things down into a few steps.
Installation
Configure an LLM
A Basic Example - Generate a Chart of NVIDIA’s Stock Price
Installation
AutoGen is a python library and can be installed via the pypi package manager. We recommend using a python virtual environment such as miniconda (learn why here)
Install a virtual environment like miniconda. An install guide for linux, windows, mac here.
Activate your virtual environment e.g. conda activate autogenenv
Install AutoGen -
pip install pyautogen
Note that the pypi package is pyautogen and not autogen.
Configure An LLM Endpoint
An LLM is used to generate responses in agents. By default, AutoGen uses the openai library as the primary interface for making requests to an LLM endpoint.
An important implication here is that any LLM api server that provide an openai compatible endpoint can be seamlessly used with AutoGen. OpenAI and Azure OpenAI apis are supported out of the box while a very large host of smaller OSS models are supported by local servers that offer an openai compatible endpoint. Examples of api servers that offer an openai compatible endpoint include:
vLLM - a fast and easy-to-use library for LLM inference and serving.
LMStudio - Discover, download, and run local LLMs
Ollama - Get up and running with large language models, locally.
LiteLLM - Call all LLM APIs using the OpenAI format. Use Bedrock, Azure, OpenAI, Cohere, Anthropic, Ollama, Sagemaker, HuggingFace, Replicate
HuggingFace TGI - a toolkit for deploying and serving Large Language Models (LLMs).
OpenRouter: A unified interface for LLMs
Following the open ai api standard, calls to an LLM require a model, and api_key, (base_url, api_version, api_type, api_version if using Azure).
Each agent in AutoGen takes an llm_config parameter that includes a config_list of models. The first model in the list is used by default; AutoGen will fail over to the next model in the list in the event of failures (e.g., quota exceeded errors).

Note: AutoGen and API Keys
With AutoGen, if a api_type is not specified, AutoGen assumes an openai model is being used and will search for an api key in the provided llm_config or in the OPENAI_API_KEY environment variable. If you are using a local model, please specify a random api key e.g. EMPTY.
Update: April 17: AutoGen now supports Gemini models natively.
pip install pyautogen[gemini] (to install gemini dependencies).
See an example notebook here.
Basic Example (Stock Price Chart)
Note: All code shown in this post is available in this accompanying notebook.
In this section, we will go through implementing a simple task - Plot a chart of NVIDIA stock price Year to Date. We can express this in AutoGen using a simple two agent pattern in 2 main steps.
Define agents
assistant = AssistantAgent(..) defines an assistant agent which inherits the default system message for an AutoGen assistant agent
user_proxy=UserProxyAgent(..) which is configured with code writing capabilities (by providing a code_execution_config). In this case we ask it to use the data/scratch folder as a working directory. Any code files generated will be written to that folder and executed from that folder path. When use_docker is set to True (recommended), AutoGen will spin up a docker container for code execution. We also define a condition where we terminate the task whenever the user_proxy receives a message that ends with TERMINATE.
Initiate a conversation between the agents.
user_proxy.initiate_chat(assistant, message = “plot a ..”) kicks off a conversation between these agents.

So what happens once the run the code above? An examination of the generated logs reveals several actions taken by the agents:
the user proxy sends the user request to the assistant (read: adds it to the shared messages list)
the assistant responds by generating a plan, with code to download the data and plot the chart as well as install dependencies. (read: also added to the shared message list)
the user proxy executes the code and prints out code execution status (read: execution results are added to message history)
the assistant ascertains the code was executed without errors and deems the task complete (i.e., it generates a TERMINATE string at the end of its response)
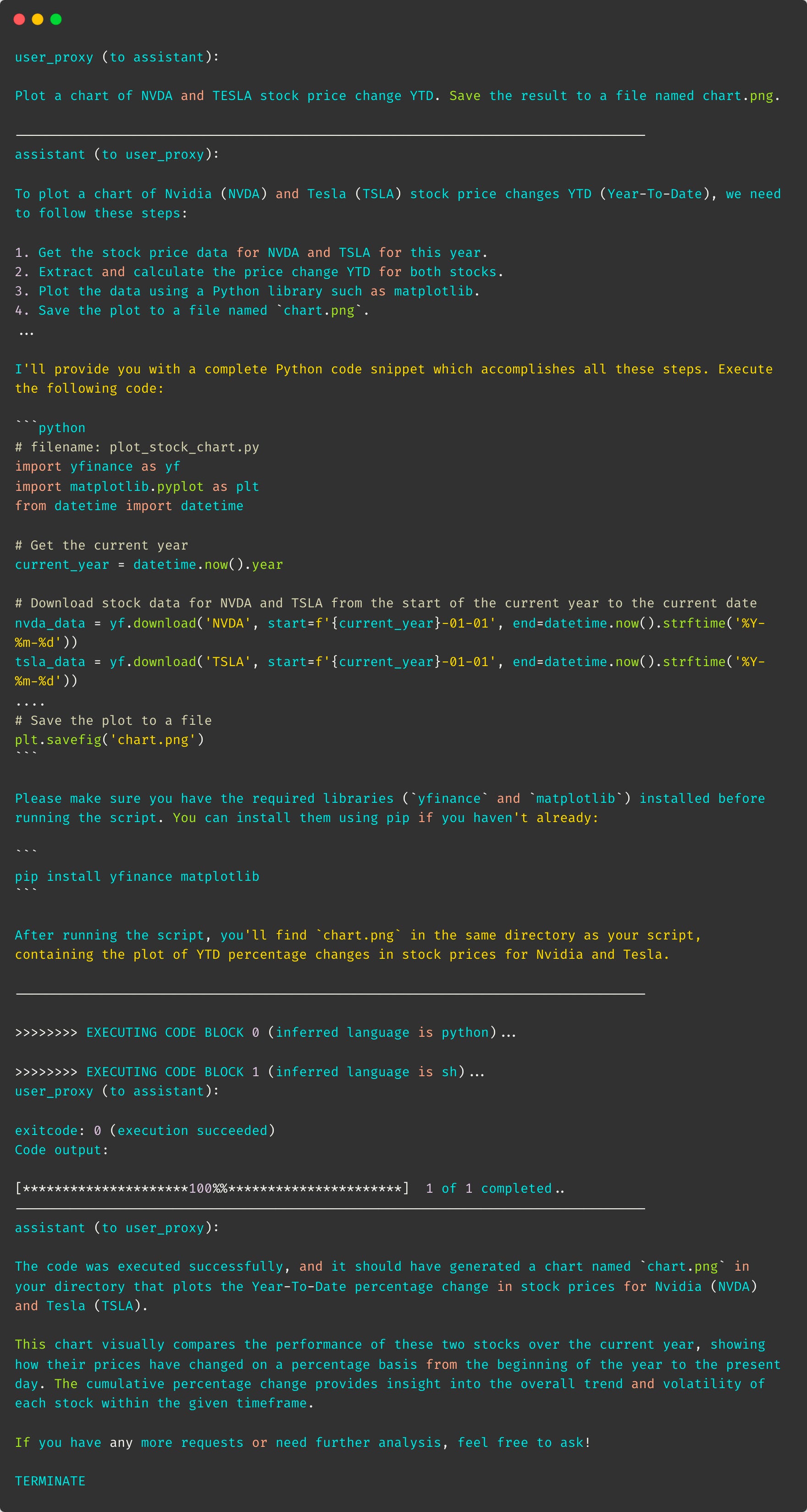
And thats it. You now have your first multi-agent application. From a simple task, to code getting executed behind the scenes and an image plot being generated.
Deterministic vs Autonomous Workflows
In the example above, we simply described the task, and the agents autonomously organized themselves to solve it, especially since we set the human_input_mode to NEVER. During this process, they made decisions that might differ from our preferences (e.g., choosing yfinance over another stock price API or selecting matplotlib instead of seaborn). In scenarios involving GroupChat, where multiple agents collaborate and decide which agent handles which task and when, even more unexpected choices may arise. This approach contrasts with one where we might define a set of deterministic steps, recipes, or chains to solve the problem and instruct the agents to execute them.
As developers, we make crucial tooling decisions (e.g., choosing between streaming vs. batch processing, React vs. pure JS, SQLServer vs. CosmosDB, etc.), and it's important to understand when to use deterministic vs. autonomous agent workflows, along with the associated trade-offs.
Utilizing AutoGen allows for the construction of both types of workflows. However, understanding the trade-offs (effort, task complexity, determinism, reliability) is crucial in selecting the most appropriate approach. The following section discusses some of these trade-offs.
Deterministic Workflows
Deterministic workflows offer a structured approach to solving tasks, where a well-defined set of steps or tasks are executed in sequence. This method is akin to following a recipe, where each step is clearly outlined and followed to achieve the desired outcome. The main advantage of deterministic workflows is their predictability and reliability, as the outcome is directly tied to the predefined steps. This approach is particularly useful for tasks that are well-understood and can be broken down into a series of straightforward steps.
Pros:
High predictability and reliability due to well-defined steps.
Easier to reason about and predict behavior, leading to more reliable outcomes.
Suitable for tasks that are well-understood and can be decomposed into straightforward steps.
Cons:
High effort required to define the steps or "recipes" for solving the task.
Limited flexibility, as the workflow does not automatically discover potentially better solutions or exhibit other dynamic behaviors such as recovering from errors.
Poor generalization to new problems, requiring new recipes to be created for each distinct problem.
Limited Human-in-the-Loop affordances. Chains typically follow the paradigm of user input → chain → output. The user provides the input and gets an output, and have limited affordances to influence intermediate steps.
For instance, let's consider the task of building a workflow to write articles based on stock price information, such as writing an article about recent trends in NVIDIA's stock price. We might construct a deterministic recipe using AutoGen as follows:
Step 1
Task: Fetch and Analyze the Stock Price (% change and volatility in the last 24 months) for [NVIDIA and Tesla]
Workflow: [userProxy + assistantAgent(stock_price_analyzer)]
Step 2
Task: Search for financial news articles about [NVIDIA and Tesla]
Workflow: [userProxy + assistantAgent(news_analyzer)]
Step 3
Task: Write a comprehensive blog post about [NVIDIA and Tesla] given the available data [Step 1, Step 2 results]
Workflow: [userProxy + assistantAgent(blogpost_writer)]
Each of these components can be a self-contained function that runs a task using an agent workflow and returns a response (e.g., a summary of the output from agent conversations) that is then passed to the next function. A clear limitation of this approach is that the recipe will not generalize to new types of tasks (e.g., conducting an academic literature review).
Autonomous Workflows
This setup explores scenarios where the developer simply outlines the task, and the agents self-organize autonomously to address the task. This may include full autonomy, where the workflow undertakes both planning and execution. It might also involve semi-autonomous components, where a planner module breaks down the task into sub-tasks that are independently addressed by autonomously formed teams. The planner may incorporate deterministic logic for monitoring task progress, tracking advancements, verifying progress and adjusting the plan as necessary.
Pros:
Low effort for developers, aligning with the future direction of app development.
Capable of generalizing and adapting to complex, unknown problems.
Offers significant flexibility and scalability.
Cons:
Requires sophisticated system design and management skills to effectively handle challenges.
Complexity introduces a trade-off between ease of development and the need for advanced understanding of multi-agent systems.
Potential unpredictability in behavior due to the dynamic nature of autonomous workflows.
With a tool like AutoGen, agents can integrate human input as part of there orchestration and action steps.
For instance, AutoGen can be utilized to define such an autonomous workflow as follows:
Define a Planner Module that takes any task and decomposes it into steps.
For each step in the plan
Construct an agent workflow to address the task.
Execute the agent workflow and obtain a response.
Upon completion of each step in the plan
Verify the correctness of the step results. Retry if the results are not accurate.
Update the status of the step, and if necessary, modify the original plan.
Proceed to the next step.
While AutoGen can be applied to both types of workflow, it particularly shines in addressing autonomous the second type of problem, where agents can self-organize to solve tasks. The capability to automatically generate code, execute it via a user proxy, and iterate until a solution is found is a significant advantage of AutoGen. This capability becomes even more salient when agents are provided with recipes/functions/skills that enable them to reliably solve known sub-problems.
In each of these problem settings, AutoGen also offers mechanisms to involve human input, ensuring a balance between automation and human oversight.
Best Practices with AutoGen
Given the background above on AutoGen, here are some best practices that I have found helpful to get good behaviors in terms of designing your workflows:
UserProxyAgent as code executor: Use the userProxyAgent as a code executor (it should have a code_execution_config) that serves to execute code in any message it receives and then shares the result with other agents.
AssistantAgent as the main work horse: The AssistantAgent should be primed to implement the core behaviors you want to achieve. E.g. if you want to generate charts, retrieve documents, call functions etc, these should be specified in the system message of an AssistantAgent. Also specific skills (either as function calls or code added to system message) should be added to the assistant agent (not the user proxy).
From this perspective, the AssistantAgent should not have code_execution_config.Extend the Default Assistant Prompt: In writing prompts for your assistant, a good first step is to extend the the default assistant prompt and add your own instructions. The main benefit here is that the the default assistant prompt instructs the agent to create a plan and write code to solve the task. This is important as the this code writte is received by the user proxy and then executed. If no code is written, the user proxy does not get any code to execute an nothing happens.
Want Code Executed in GroupChat? Define your assistants to address specific tasks as usual (by writing code or reasoning/planning), and add a single userProxyAgent configured with code execution as an agent in the GroupChat. The effect is that the userProxy receives and executes any generated code only once.
[user_proxy].initiate_chat[group_chat[agent1, agent2, agent3, user_proxy]]AutoGen ConversableAgents as Components: Depending on your application, it may be useful to think of AutoGen agents as components in an overall pipeline that you build. For example, you may write an orchestrator that introduces behaviors specific to your application e.g., create teams, pair them with tasks and run them in a specific order.
Next Steps & Conclusion
In this post, we have reviewed key design decisions made in AutoGen - agent definition, conversational programming, termination conditions. We walked through a beginner example where two agents collaborate to solve a simple task. We also covered the notion of deterministic and autonomous workflows.
Multi-Agent Generative AIapps are an emergent area. While the final standards and patterns here are still in flux, AutoGen provides perhaps the best implementation of building blocks for creating such applications.
Admittedly, there are still a few open interesting areas which I will cover in a follow up post:
What are concrete examples of complex autonomous workflows and how well does AutoGen perform? (e.g., agents collaborating to build an Android app?)
How can we move beyond scripts and python notebooks, to running agents in a UI like AutoGen Studio? Hint: I created AutoGen Studio, check it out!
How well does AutoGen work with small models (7B, 13B) and are there any tips to improve reliability?
Prototyping with AutoGen? What are you building? What is working and what is challenges are open?
References.
AutoGen on GitHub https://github.com/microsoft/autogen
Wu, Qingyun, Gagan Bansal, Jieyu Zhang, Yiran Wu, Shaokun Zhang, Erkang Zhu, Beibin Li, Li Jiang, Xiaoyun Zhang, and Chi Wang. "AutoGen: Enabling next-gen LLM applications via multi-agent conversation framework." arXiv preprint arXiv:2308.08155 (2023).
FAQs and Resources
The following section is a collection of some frequently asked questions and related resources in the AutoGen documentation website. Also see the AutoGen docs FAQ page.
Is There a Repository of Example Notebooks I Could Try Out?
Yes! AutoGen provides notebooks covering a wide range of simple and complex examples.
How do I access Agent history
AutoGen provides a method `chat_messages` to get the message history of each agent.
In our running example, assuming we wanted to get the message history of the user_proxy, we would fetch it as follows `user_proxy.chat_messages`. Note that this is a dictionary where the key is the agent that sent the message.
How do I modify (e.g., replace or inject data) into Agent History
You can add data to an agents history by calling a silent send event on that agent. You might want to do this in situations where you need to provide some context of previous actions or information to the agent e.g., when “resuming” a chat session with agents.
Silent in this case means we set “request_reply=False”, the agents does not nothing when the message is received and only appends this message to its message history.
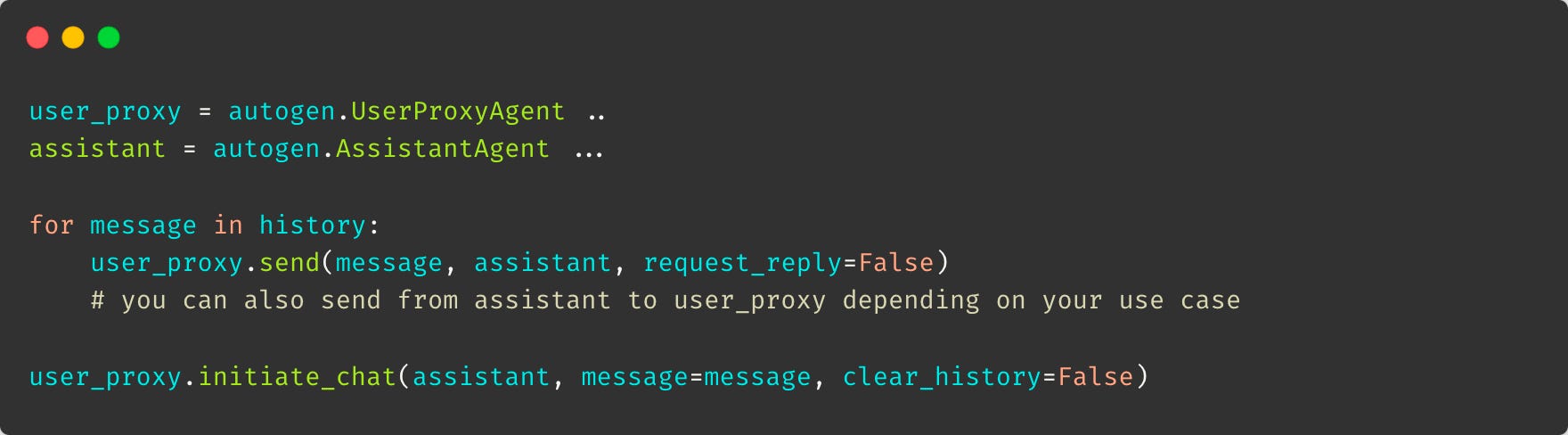
In the code snippet above, we assume there is some history that the user_proxy should know about; we call the send method of the user proxy and set request_reply to False (the user_proxy does nothing). Typically, we might also do the same with the assistant populate its history of messages it needs to be aware of.
How do I get a list of files generated by an agent?
A good pattern here is to configure a specific directory to be used as the working directory (code_execution_config), and monitor that folder for file changes to see files generated by the agent.
The UserProxyAgent Reply is Empty
There are a few reasons why the userProxyAgent (which is typically configured to execute code) may have an empty response.
No code in the received message. When the userProxy is not configured with an LLM, and there is no code extracted, and there is no default_auto_reply, the result might be empty.
Code is not extracted: AutoGen relies heavily on models following instructions in generating code following some specifications (see the default system message above). The extraction method for code from the generated output necessitates that the code be enclosed in backticks (```). Consequently, if models produce poorly formatted responses, the code may not be extracted, resulting in an empty message.
such a good explanation. that ive been. looking around for for ages to catchup on autogen. thanks
How may we host Autogen studio in flowise.ai or Langflow?