
How to Effectively Use Generative AI for Software Engineering Tasks!
Issue #25 | Instead - Here are 7 ways to get the most of Generative AI pair programming tools like Gemini, ChatGPT or Claude


It's no longer a question of whether to use GenAI tools, but how to use them effectively. Just as digital literacy was crucial for navigating the internet era, AI literacy is becoming essential for engineers to achieve equitable outcomes from AI tools.

For the beginner software engineer, it is very tempting to begin by simply asking the LLM to "write code to do X". In fact, the majority of tutorials that explore guiding users on how to integrate LLM in their software engineering or data science workflow begin with this step.
I think that is probably the wrong thing to do.
This post is a reflection on some of my observations heavily using LLMs as part of my day to day software engineering workflow and the emerging strategies I have followed.
TLDR
Don't start by asking LLMs to write code directly, instead analyze and provide context
Provide complete context upfront and verify what the LLM needs
Ask probing questions and challenge assumptions
Watch for subtle mistakes (outdated APIs, mixed syntax)
Checkpoint progress to avoid context pollution
Understand every line to maintain knowledge parity
Invest in upfront design
An important or useful mindset to have within all of this is to treat the model/system/agent as a junior but competent pair programming colleague, while also realizing that LLMs are autoregressive next token generators.
Note: This post focuses on a chat workflow e.g., while using an interface like Gemini, ChatGPT or Claude where the developer directly drives the interaction and context. The opposite of this being a workflow like GitHub Copilot or Cursor where context is inferred.
1. Don't Write Code - Analyze First!
Experience has taught me that the best results come when I instruct the model to NOT WRITE CODE immediately. Instead, I start with a message like this:
I need help refactoring some code.
Please pay full attention.
Think deeply and confirm with me before you make any changes.
We might be working with code/libs where the API has changed so be mindful of that.
If there is any file you need to inspect to get a better sense, let me know.
As a rule, do not write code. Plan, reason and confirm first.
---
I refactored my db manager class, how should I refactor my tests to fit the changes?Half the time, the LLM will make massive assumptions about your code and problem (e.g., about data types, about the behaviors of imported functions, about unnecessary optimizations, necessary optimization, etc.). Instead, prime it to be upfront about those assumptions. More importantly, spend time correcting the plan and closing gaps before any code is written.
2. Focus on Providing Context
Context is absolutely critical. It's like trying to solve a puzzle with a colleague - you typically don’t want any pieces hidden from them, would you? This is also akin to a design meetings that typically begin with the senior dev providing a “lay of the land” of the codebase and offering to answer questions.
I've learned to start by asking the LLM "what context do you need?" Sometimes, what seems obvious to us isn't visible to the AI at all. A component bug might exist simply because the LLM cannot see the JSON or types it's supposed to process, or because the JSON structure has changed.
What do you need ?
Here are some files ..?
I use ant design for components, tailwindcss for layout and lucide-react for icons
All of this saves you time -saves you time correcting mistakes the LLM will make without the context.
3. Ask Many Questions, Learn
Sometimes, your task is to implement new features, get up to speed with some new codebase e.t.c. In these scenarios you can think of your codebase as a game map with undiscovered locations, where the AI tool can help you uncover new sections - and more importantly learn. Experience has taught me to:
Push for deeper understanding of side effects
Challenge assumptions about implementation
Ask for pros and cons of different approaches.
Probe for edge cases that might break the solution
Ask for options .. (e.g., I have found it insightful to ask for alternative algorithms to what I have, alternate libraries etc).
Note that LLMs will often converge to the mean solution. This is particularly problematic because many niche use cases need formulas and accommodations that are at the long tail of possibilities. Your senior engineer instinct should kick in here - if you don't ask these questions, you'll end up with mistakes that are even more difficult to find and debug.

In many cases it is important to prompt the model to explore the space of ideas and not present any opinion. Assuming the goal is to build a visualization component, there is potentially a wrong and right way to work best with an LLM
Right: What are good options with pros and cons for visualizing a multiline area chart? This way the LLM can list out options and you can make the decision, while also learning about directions you probably have not considered.
Wrong: Should I use ReChart? The LLM is very likely to say yes even if the context and other factors make it the suboptimal choice. Simply mentioning ReChart, fixes the direction of the LLM’s response. Recall, LLMs are autoregressive machines.
4. Watch out for Subtle Mistakes
Responses from LLMs often contain mistakes - but subtle ones. Some common patterns that you should watch out for:
Using outdated versions of libraries (even when explicitly told not to)
Mixing syntax from different language versions
Making subtle changes to common formulas, especially in niche cases. (imagine you have an app where pi = 22/7.5 ; the model might silently modify this to 22/7).
Relying on old API documentation or specifications that have changed
Writing unmaintainable code. Examples: Related functionality littered across multiple files; massive components with thousands of lines of code, duplicated functionality across the code base. Without supervision, an LLM can code you into a corner - code that is not modular and extensible.
While iterating on on an early idea v0, the model will frequently do things like “I will leave this function in the code base for backward compatibility” leading to tonnes of deadcode around.
Proposes functionality that already exists, or adding related functionality in unrelated parts of the code base.
Problematic and downright dumb shortcuts e.g., typing values as Any just to fulfil typing instructions or assertions to true to pass tests
The world of software is dynamic - APIs change, specifications evolve, and the model's knowledge is frozen in time - or atleast to the last train run. You need to be the one to catch these discrepancies.
5. CheckPoint Progress - Reset State
As you collaboratively explore with a model, creating multiple versions of a file, fixing errors, providing feedback, all of that is “seen” by the model and can introduce noise.
An AI model has a context window - the maximum amount of text it can process at any given time. Also as there is more text in the context, it is more likely to make mistakes.
For example, new versions of a component might sneak in errors that were fixed earlier, affected by bugs that were discussed earlier but still persist in the conversation's context. Experience has taught me that when I iterate on a component and create new versions, once I arrive at something I'm happy with, I typically will:
Save the current stable version of whatever is being built at given intervals (aka checkpoint).
A good practice is to verify updates “Here is the current version, are there any issues?”
Create a new chat session with fresh context, relevant information
Break down complex tasks into smaller, refactored subcomponents. Only reference (e.g., via imports) subcomponents that have stable/reliable behavior
This means the core logic takes up less model context
There is less surface to introduce bugs in stable components.
This approach helps maintain clarity and prevents context pollution that can lead to subtle bugs.
6. Aim for knowledge parity.
Perhaps the biggest risk of AI is that it's probably the first tool that can honestly keep developers dumb. Unlike the typewriter or printing press where their work was entirely manual, it is possible to write (vibe code) a really complex application that appears to work (and probably does) without the writer knowing anything about how the app works.
Nick Potkalitsky writes about how models could adversely affect learning.
This is perhaps not a good outcome and can lead to runaway complex systems - everywhere. If you thought AI slop was bad, think of systems much more complex handling transactions, running on our PCs, but being "sort of" functional. Also, how do you fix it when things go wrong?
My advice:
Fight the urge to accept code without carefully reading each line
Ask questions about any patterns or approaches you don't understand
Use the LLM to explain complex concepts - it's never been easier to learn!
Build your understanding alongside the solution
7. Invest in Good Design
As a developer, you'll frequently be tasked with creating new features. This often involves building upon existing design conventions that you or your team have established—whether extending base classes or following specific patterns. As you leverage an LLM as part of the development process, existing code becomes part of the context and will inevitably influence future directions. Existing code with poor designs will leave room for generated buggy code, while a good foundational design will naturally guide the LLM toward producing cleaner, more maintainable solutions. This compounding effect makes upfront investment in good architecture even more crucial when working with AI-assisted development.
Where do agents fit into all this?
The astute reader will realize that some of the strategies above could potentially be abstracted into an agent.
For example, an agent could assemble the right context, decompose tasks into smaller steps, include critique agents that questions that verify responses etc. This automation could create a more efficient developer workflow and save time.
In fact, a recent paper [1] from my group explores how we can build a generalist multi-agent system that can do things like take a plan, decompose it into steps, assign steps to independent agents, review progress, checkpoint and reset state.
Magentic-One is a high-performing generalist agentic system that employs a multi-agent architecture where a lead agent, the Orchestrator, directs four other agents to solve tasks. The Orchestrator plans, tracks progress, and re-plans to recover from errors, while directing specialized agents to perform tasks like operating a web browser, navigating local files, or writing and executing Python code.
Also, in my upcoming book (Published by Manning, expected Spring 2025), I reflect on how the software engineering discipline is evolving and how multi-agent systems can be designed to enable these more effective workflows.
Consider pre-ordering to learn more.
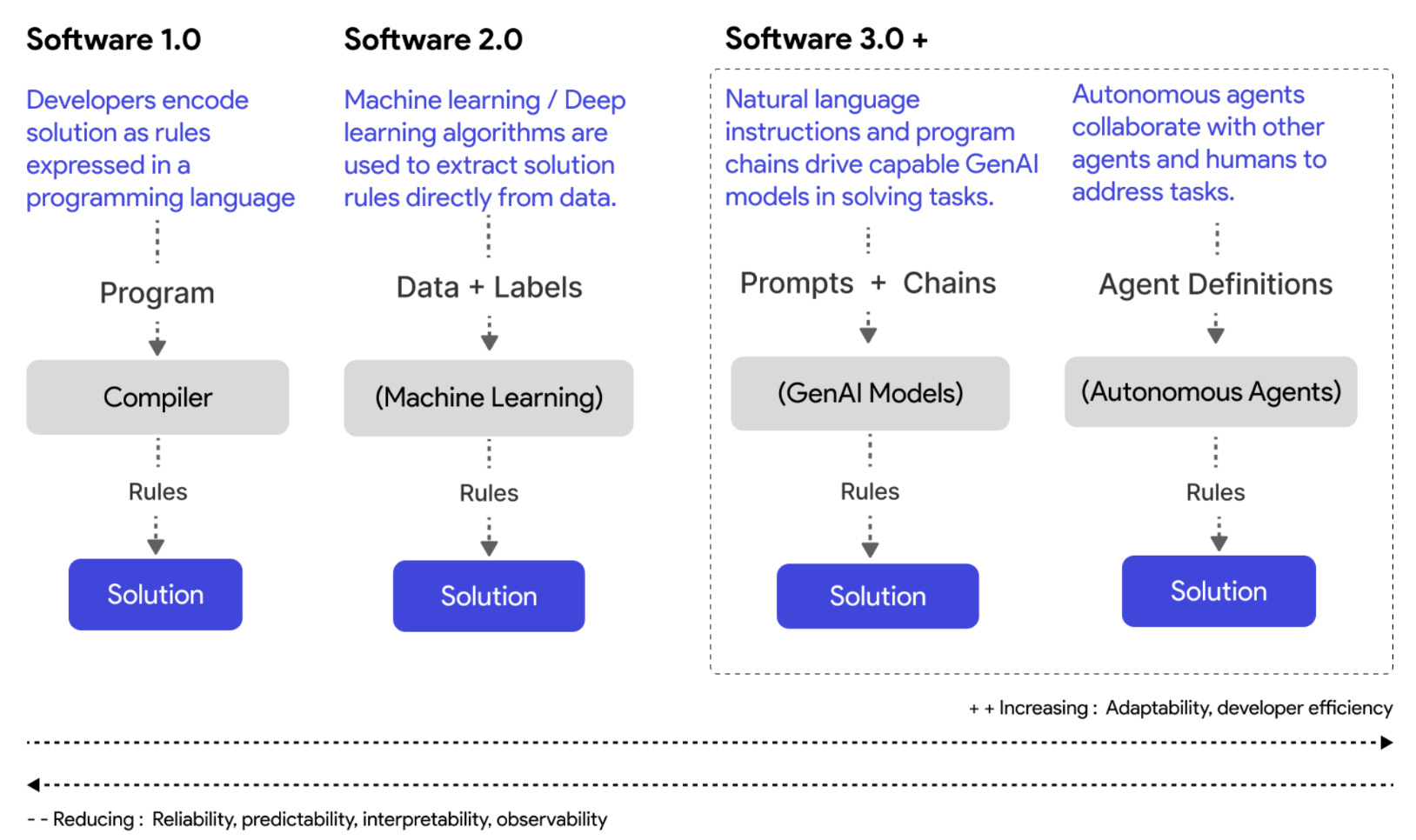

Also, tools like GitHub Copilot, Cursor help with elements of finding the right context and automatically providing helpful suggestions.
The Role of UX and Theory
As someone with a background in human-computer interaction, I view LLM interactions through the lens of communication and psychology theories. These theories help us understand what enables or impedes effective communication between parties.
Media Richness Theory (MRT) is particularly relevant here, as it helps explain the dynamics of human-AI communication - a variation from the traditional human-human interaction in pair programming. Both scenarios require effective communication, but with AI, the interface becomes even more critical.
Media Richness Theory, developed by Daft and Lengel in 1986, proposes that communication media vary in their ability to facilitate understanding. "Rich" media handle multiple information cues simultaneously, enable rapid feedback, and support natural language and personal focus. The theory suggests matching communication medium to task complexity. I have explored an MRT lens in a previous paper[3] on interfaces for image generation models
For example, the Claude.ai interface demonstrates key MRT principles: its artifacts view provides multiple information cues through versioned code displays, the chat interface enables rapid feedback, and the ability to upload context files helps establish shared understanding.
Also, the AutoGen Studio [2] interface visualizes messages exchanged by agents as they address tasks including the cost of each step (in tokens), facilitating understanding of system behaviors.
These design choices aren't arbitrary - they're grounded in how humans effectively communicate and collaborate. The UX becomes the medium that enables or constrains this collaboration.
LLMs are powerful tools, but their effectiveness ultimately depends on the interface that mediates our interaction with them. Theory-informed UX design isn't just nice to have - it is essential for unlocking the full potential of these systems.
Dibia, V. (2024). How to Effectively Use Generative AI for Software Engineering Tasks. Self-published on newsletter.victordibia.com.
BibTeX:
@article{dibia2024effective_genai,
author = {Victor Dibia},
title = {How to Effectively Use Generative AI for Software Engineering Tasks},
year = {2024},
url = {https://newsletter.victordibia.com/p/developers-stop-asking-llms-genai},
publisher = {Self-published}
}References
Fourney, Adam, Gagan Bansal, Hussein Mozannar, Cheng Tan, Eduardo Salinas, Friederike Niedtner, Grace Proebsting et al. "Magentic-One: A Generalist Multi-Agent System for Solving Complex Tasks." arXiv preprint arXiv:2411.04468 (2024).
Dibia, Victor, Jingya Chen, Gagan Bansal, Suff Syed, Adam Fourney, Erkang Zhu, Chi Wang, and Saleema Amershi. "AUTOGEN STUDIO: A No-Code Developer Tool for Building and Debugging Multi-Agent Systems." In Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, pp. 72-79. 2024.
Interaction Design for Systems that Integrate Image Generation Models: A Case Study with Peacasso. Victor Dibia (2024) https://github.com/victordibia/peacasso
If you have used LLMs extensively as part of your workflow .. what are some practices you have adopted to be more efficient aka - get the right answers with the minimal number of tries.