
Machine Learning Models that Generate High Quality Images from Text - Issue #10

The ability to generate high quality novel images has been the target of extensive research in the deep learning and computer vision field. The promise of simply describing an image using natural language, and a tool generates high quality images that are faithful to that description is .. a significant achievement given the recent state of affairs. Importantly, this could supercharge creativity for a wide swath of users with varying image creation or editing skills.
Well .. that technology is already here!
In this post, I'll walk through some examples of how a recent class of machine learning models (diffusion models) can be used in generating compelling images.
Hint: the images below were generated by a model purely based on text.

Image Generation Models
Recent advances in text-to-image generation models have made the image generation promise a reality. We have seen models like DALLE-2 (April 2022) that really demonstrated the art of the possible, followed by the open source release of the stable diffusion model (August 2022). Both of these advances are based on diffusion models - models that learn a noising process (adding noise to some input sample across several steps until that input is indistinguishable from pure noise) and a denoising process that reverses the noising process (removes noise across several steps based on some guidance from text, until a legit image is recovered).
Latent Diffusion Models: Components and Denoising Steps | Victor Dibia — victordibia.com The ability to generate high quality novel images has been the target of extensive research in the deep learning and computer vision field…
Once this noising/denoising process is learned (during training), we can use the resulting model to generate images based on some text. To illustrate, in the figure below, the model starts with what looks like random noise (top left) and at each denoising step (each box corresponds to output from the model at some intermediate step) it attempts to improve this image (by removing noise) until we get the final image. How does it know which pixels and regions of the image to improve? - well it does that by using signals from the text you provide.
A diffusion model has multiple component (e.g., a UNET, A text encoder, schedule, VAE), but those are beyond the scope of this post. See the latent diffusion paper for technical details on how the model works.

Based on the components of diffusion models, there are 3 ways in which the user can guide/control the content of the image generated:
Text-to-image : Here a prompt is provided in the form of text and the model generates an image based on the prompt.
Text+Image-to-image : The user can upload an image and a text prompt and the model generates an image based on the prompt and the image.
Image In painting (Text+Image+Mask-to-image ): The user can upload an image, edit the image (erase portions of it which are captured as a mask over the original image) + a text prompt and the model generates an image based on the mask, the original the image and the text prompt.
In the next section, we will explore concrete examples of how these control modalities can be applied in creating artistic images.
Generating Images with Diffusion Models
Perhaps the easiest way to try out an image generation model is to sign up for access to the DALLE-2 model from openai (you get some initial credits to start) or the dreamstudio UI from the folks that released stable diffusion. Alternatively, you could run your own version of the open source stable diffusion model and use any of the opensource UI tools available to interact with the model.
In this post I will be using Peacasso - A UI tool for interacting with the stable diffusion model. Disclaimer - I created Peacasso (and feedback is welcome, thank you!)
Let us explore 3 steps in the creative process.
Step 1: Select a Prompt
A prompt is some text description of what you want to generate. For example, we can provide the following text to a model -, a picture of a porcelain face - and we get the following image:

This image looks nice. It has the porcelain texture which is great, but it is not particularly unique nor has the stand out factor.
In practice, it can be more involved than just invoking your prose skills in coming up with an effective prompt. This usually involves adding specific qualifier terms (e.g. close up, 50mm camera, hyper-realistic, etc) or artistic styles (style of van gogh, claude monet, picasso etc). These qualifier terms and art styles can help further guide the model towards generating high quality images.
But there is one problem - how does a new user figure out the right set of qualifier terms and styles that yield good results? You could browse through a collection (like lexica.art ) of examples created by experienced artists who have worked with these models and discovered prompts that work well. There, we can find a prompt with engaging results like the one below and try it.
Complex 3d render ultra detailed of a beautiful porcelain profile weeknd face, biomechanical cyborg, analog, 150 mm lens, beautiful natural soft rim light, big leaves and stems, roots, fine foliage lace, silver red white details, massai warrior, alexander mcqueen high fashion haute couture, pearl earring, art nouveau fashion embroidered, steampunk, intricate details, mesh wire, mandelbrot fractal, anatomical, facial muscles, cable wires, microchip, elegant, hyper realistic, ultra detailed, octane render, h.r. giger style, volumetric lighting, 8k post-production

The results of using a more complex prompt immediately gives more interesting results. Note the use of modifiers like complex 3d render, soft rim light, volumetric lighting, 8k and artistic styles like giger style, alexander mcqueen.
We can then repeat this initial process multiple times until we find an image that looks great! Depending on the model configuration, every run yields a random new set of results.
Fascinating!
Step 2 - Generating Image Variations (Image to Image Variations)
With image generation models, we can use the image-image mode to explore generating more variations of an existing image. In the example below, we take one of our images from the previous step (top left), and then pass it as a reference image plus the same prompt.

Note how each of the generated images have similarities to the reference image (face orientation, facial structure, colors, plain background etc).
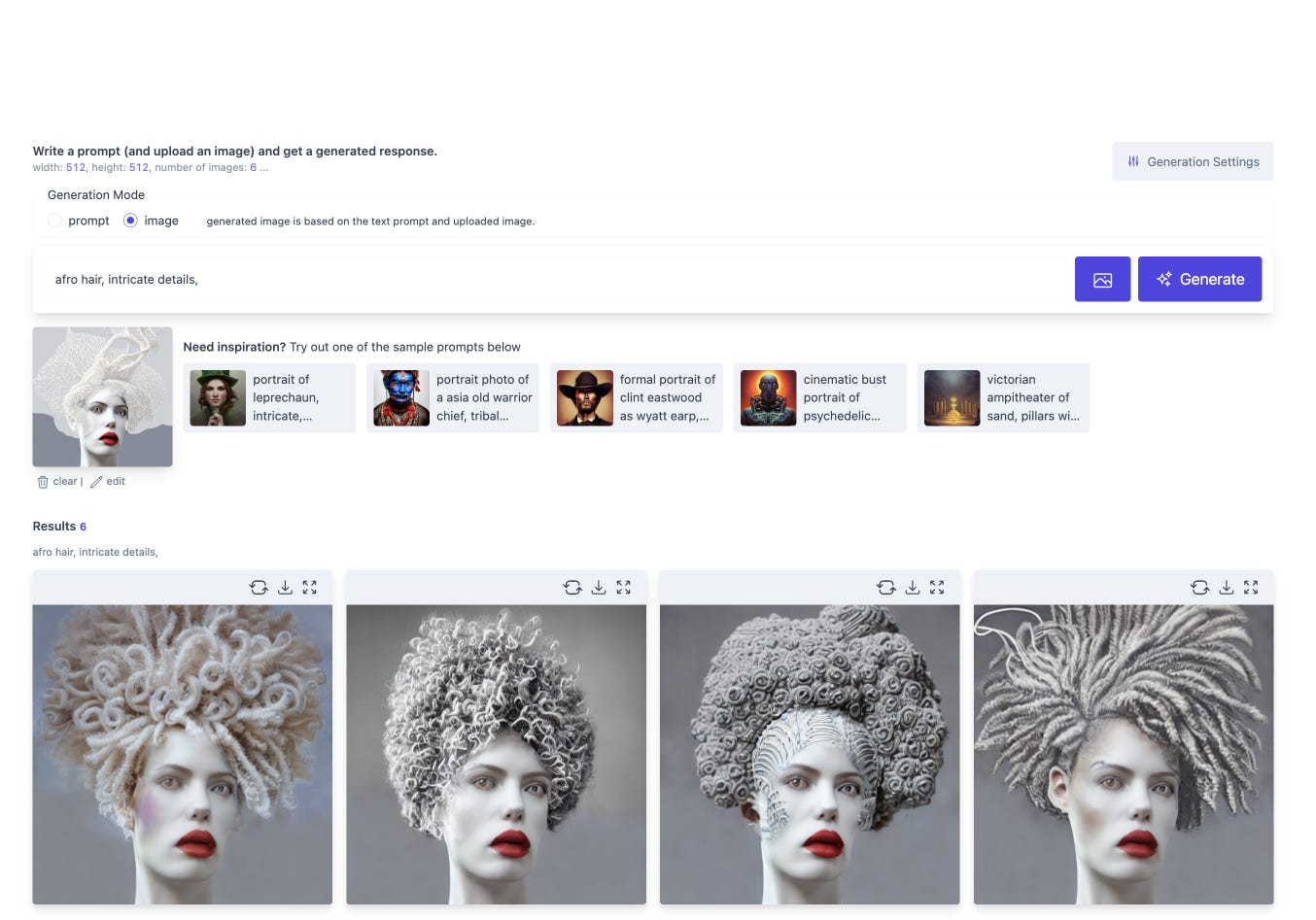
Step 3: Modifying Images (Masking + Inpainting)
At this point, I have an image that I like but want to edit only some parts of it. I'd like to replace the hair. To achieve this, we can create a mask that specifies what part of the image to modify - essentially getting the model to delete and regenerate parts of an existing image. In the example below, we provide a mask and then a text description (Afro Hair) of what we want the model to generate in the deleted portion.

Advances in Model Architecture
While latent diffusion models have made the case for generating high quality images on consumer GPU devices, this trend has been extended with improvements in model architecture resulting in improved quality.
Scalable Diffusion Models: Train latent diffusion models of images, replacing the commonly-used U-Net backbone with a transformer that operates on latent patches.
Rectified Flow Models: Presents a novel transformer-based architecture for text-to-image generation that uses separate weights for the two modalities and enables a bidirectional flow of information between image and text tokens, improving text comprehension, typography, and human preference ratings.
A recent model released by Black Forest Labs - FLUX generates images that use some of these advances above. Code and weights here.

In the background of the mountains is the word "VICTOR" written in the air in artistic prominent white smoke lettering
Parting Thoughts - UXD is Key!
Image generation models of today are capable of generating stunning, arresting imagery! However, this process often requires a bit of effort as well as trial and error.
I am betting that the most innovative applications of this technology will be unlocked by good user interfaces and user experience design! Tools that answer the question - how do we reduce the cognitive effort required to go from idea to satisfactory high quality imagery.
As mentioned earlier, all of the images here are created using Peacasso. Feel free to try it out, or DALLE-2 or any other interface available.
If you'd like to discuss image generation models some more, reach out on twitter!
Until next time, be well!